
引言 Service Locator 是 Java™ 2 EntERPrise Edition (J2EE) 应用程序中一个比较流行的应用程序设计模式。这个模式通过目录服务封装访问组件的代码,如 JNDI 客户端代码之类,因此客户端可以简单的以资源名通过验证并返回这个资源。服务定位器实现通常包括资源缓存,以此来避免对相同资源的重复查找。然而这只能在 J2EE 1.2 中正常工作,但在 J2EE 1.3 和以后的版本中,缓存可以在应用程序部署中引入微妙且难以诊断的错误。因此,在 J2EE 1.3 应用程序中,服务定位器的实现不应该包含资源缓存。 JNDI 目录服务 Java Naming and Directory Interface(JNDI)是 J2EE 平台的一部分,它使得 Java 程序可以通过唯一的名称来访问资源,而并不用考虑资源是在何处存储的、它是如何实现的、容器以及它的 JNDI 提供者是如何实际访问资源的;资源可以是任何程序需要全局访问的对象。 我们将主要回顾 JNDI 是如何工作的,首先要弄清楚影响 Service Locator 模式的部分。要了解更多,请参见 Sun 的 JNDI 指南(参见 参考资料)。 JNDI 上下文 JNDI 名是以层次树结构排列的,就像文件系统的目录结构或一系列 Java 类的包结构。在 J2EE 中有对资源的通用类型的 JNDI 资源环境引用子上下文名的约定。表 1 显示了典型的 JNDI 子上下文和类型。 表 1
每个子上下文名被用作 JNDI 表达式的一部分,以此来访问客户端本地上下文中的对象。例如, java:comp/env/ejb 提供对 EJB 本地接口的访问,而 java:comp/env/jdbc 提供对 JDBC 数据源的访问。 为何使用 JNDI? 正如大部分 J2EE 服务一样,JNDI 只提供了标准接口(在 javax.naming 包中定义)而没有具体实现。作为透明性 JNDI 提供的例子之一,设想一个 JMS 应用程序提供者(例如 WebSphere® MQ),它是由一组受控对象来配置的(连接工厂和接收站),而组件应用程序将使用这些对象处理消息。提供者将组织这些资源并将其安排在某个目录中(或有可能在许多目录中,例如每个受控对象类型对应一个目录),这就使得应用程序通过它的名称访问组件。这个目录结构可能是厂商指定的,但因为提供者实现了 JMS 规范,所以提供者也必须确保能够通过 JNDI API 得到它的资源,而不用管实际的目录是如何实现的。JNDI 提供对资源的一致访问,而这些资源不一定是一致的。 而且,展示于应用程序面前的是一个单独的个体,连续的 JNDI 树可以(通常是“肯定”)将几个不同的提供者的资源集合在一起。JNDI 将这个细节从应用程序中隐藏了起来,因此代码只需知道资源的名称,而不用知道诸如提供者所包含资源的内容、如何对提供者进行访问、提供者为资源使用什么样的名称等等。 J2EE 应用程序服务器(例如 WebSphere Application Server)实现其自身的 JNDI 目录,服务器的应用程序正是使用它来访问所有资源。应用程序服务器需要构造 JDBC、JMS 和其他资源,使其适用于服务器的应用程序。因为提供者通过 JNDI 提供他们的资源,所以应用程序服务器的 JNDI 树可以轻易地包含资源节点。 图 1. 应用程序服务器 JNDI 树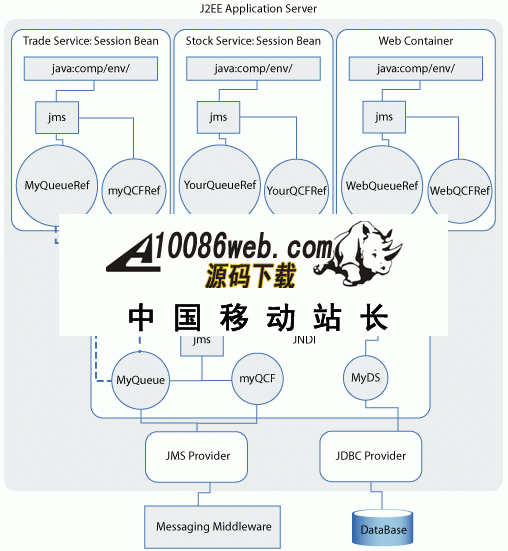 EJB 组件甚至并不知道其中的一些资源是远程的并且是在 EJB 容器之外被管理的。它通过相同的 JNDI 树以相同的方式访问所有的资源。这是组件重用的很重要的部分:组件访问资源而不用确切的了解资源是如何被提供的能力。 如何使用 JNDI 使用 JNDI,代码可以访问其组件的 JNDI 上下文并且使用它执行 查看,这是 JNDI 的一项操作,该操作接收一个名称并返回该名称的一个对象的绑定,这很像是 java.util.Map 对象中的 get(Object) 方法。 既然 JNDI 可以被用来将任何类型的对象绑定到一个名称,J2EE 就主要适用 JNDI 来提供对 资源的访问。通过 JNDI 查找访问资源,组件以 资源名方式传递,然后返回在部署描述符中由 资源引用元素所描述的资源。资源的大部分类型实际上都是 资源工厂,容器以此来控制实例的产生、缓冲池的组合以及共享资源连接。资源工厂类型的例子包括: javax.ejb.EJBHome、 javax.ejb.EJBLocalHome、 javax.sql.DataSource 以及 javax.jms.ConnectionFactory。 举例来说,下面的代码片断使用 JNDI 来查找资源名 jdbc/datasource,它返回一个资源工厂: DataSource 对象。
以此方式,代码可以脱离容器的资源管理而仍然可以轻易的通过资源的名称访问资源。代码与容器之间只需在名称的使用上达成一致就可以。 资源名映射 资源实际上是有两个互相分离但又在 J2EE 中互有关联的名称: 资源引用名:资源引用的名称,是代码部分用来识别资源之用。 JNDI 名:容器用来识别资源的名称。 有了这种安排,代码和容器甚至在资源所使用的名称上不用达成一致。当代码被部署时,部署者(J2EE 管理员,在容器中安装应用程序组件的那个人)使用部署工具将每个资源引用名都映射到与它对应的 JNDI 名称上。 举例来说,代码可能要引用一个叫 jdbc/AccountDB 的数据库。此时,账户数据可能存储在 Cloudscape® 数据库中,这样容器所引用的就是 jdbc/Cloudscape。部署者将资源引用名 jdbc/AccountDB 绑定到 JNDI 名 jdbc/Cloudscape: 表 2
然后在实际运作中,当代码访问 AccountDB 时,它将得到 Cloudscape 数据库。 应用程序资源名辖区 在 J2EE 1.2 中,资源名都是全局的,因此当两个组件引用相同资源名时,他们得到相同的资源引用,这是因为一个资源名映射到一个资源。在 J2EE 1.3 中开始,每个组件(也就是说,每个 EJB bean 类和每个 Web 应用程序)定义其自身的一套资源名,在这里每个组件的资源名与容器资源名互相独立。 这个改变对 J2EE 1.3 规范的影响是在其中加上了单独的一段,在 J2EE.5.4.1.2 "在部署描述符中声明资源管理器连接工厂引用。" 部分,其中阐述道: 其它的应用程序组件可以使用相同的资源引用名而不冲突(参见 参考资料中的 J2EE 1.2 和 1.3 规范)。 这意味着两个组件可以指向相同的资源名,而在实际运作当中却被绑定去访问两个不同的容器资源。可以认为这是 重载资源名。在两个不同的组件中相同的资源名实际上是映射到两个不同的容器资源。因此,要了解重载名是引用哪个资源,两组件中的一个也必须了解使用重载名的那个组件,并且知道那个组件是如何被映射到容器名的。 重载名举例 例如,应用程序可以包含两个会话 bean: EmployeeBean:允许用户(公司雇员)访问多个客户的账户及其他有关账户的机密信息。 CustomerBean: 允许用户(客户)访问他们个人账户。 简单的说,两个 bean 都可以使用资源名 jdbc/AccountDB,这是因为他们都使用客户账户数据库。管理员为访问数据库会定义一个数据源,称为 jdbc/AccountDS,然后在部署时期将两个组件中的 jdbc/AccountDB 绑定到 jdbc/AccountDS。 表 3
此时,资源名 jdbc/AccountDB 还没有重载,因为它总是映射到相同的容器资源。资源名是共享的,因为它被多个组件所使用,但是它没有被重载。 现在,让我们讨论一下已经需要我们来考虑的管理问题。客户可以访问并甚至能改变在账户数据库中的机密数据,而这些数据应当只能由公司的雇员来更改。业务需求指出,特定的数据库表应当只能由雇员来操作而不是被顾客操作。为了实施这一点,数据库管理员创建两个分离的登录,一个是雇员使用的,一个是顾客使用的。顾客登录不能访问存储机密数据的表,而只有对特定表的只读权限;雇员登录拥有全部的访问权限。通过这种方式,即使 Java 应用程序有错误发生,允许顾客访问这些表,数据库也会阻止顾客的这种访问。 为支持这个新的需求,使用这些新的数据库登录,部署者在容器中配置两个分离的数据源,分别对应两个登录。这两个数据源分别称作: jdbc/AccountEmployeeDS 和 jdbc/AccountCustomerDS。在部署时期,部署者分别对应的绑定资源名: 表 4
应用程序资源名 jdbc/AccountDB 现在已经是重载的名称了。它所引用的资源,雇员访问的数据源或顾客访问的数据源,要使用哪个数据源取决于是哪个组件在使用资源名。 以这种方式,部署者可以改变应用程序的选项来满足新的需求而不用改变代码,他只需改变容器配置及改变现有代码的部署。 同样地,这种重载资源映射可以用来使不同组件使用几个不同类型的资源: 不同的数据库,可能包含各自的一套数据,可能在不同的提供商处运行为产品。 不同的 JMS 消息系统,对业务模式来说可能是一个内部的也可能是一个外部的,可能在不同的提供商处运行为产品。 相同 Web 服务的多次部署,可能提供不同质量的服务。 重载是 J2EE 1.3 应用程序资源名的一种能力,因为他们是组件范围的。J2EE 1.2 的全局应用程序资源名是没有这种能力的。 Service Locator 模式 Service Locator 模式(参见 参考资料)是 J2EE 应用程序中著名的设计模式,它封装了需要通过目录服务(如 JNDI)查找资源的代码。业务逻辑代码使用服务定位器避免目录查找代码变得混乱,因此它很容易理解。客户端为资源传递一个唯一的标识符(资源名),服务定位器找到这个资源并把它返回给客户端。服务定位器封装 JNDI 上下文的访问、缩小并转化对相应 Java 接口的引用以及处理错误。 例如,允许客户端访问数据源的服务定位器代码表面上与此相似:
服务定位器通常作为集合来实现,因此整个应用程序(特别地,所有的代码运行在相同的 Java 虚拟机(JVM)上)使用相同的实例。(如果服务定位器类是 JAR 通用性的一部分并被多个应用程序共享,这些应用程序将共享相同的实例。)由于服务定位器基本上是无状态的,所以多个组件共享相同实例是没有问题的。 服务定位器的实现通常包括资源缓存,因此当应用程序重复访问相同的资源时,服务定位器只是在首次访问的时候执行查找。当资源查找代价很高时,缓存通过避免重复查找相同资源而提高了效率。这在服务定位器也是一个集合的时候很受用,因此从一个组件查找资源时也帮助了那个组件实例,其他相同组件类型的实例以及其他避免重复查找的组件类型实例。 包含访问数据源缓存的服务定位器实现如下:
服务定位器缓存错误 当在 J2EE 1.2 中首次使用 Service Locator 模式开发时,缓存引用是一个很好的主意,或者说至少在当时没有任何的伤害。但是自从 J2EE 1.3 开始,应用程序资源名是组件范围的,不是全局的了。因为每个组件单独映射,两个偶尔使用相同资源名的组件可能不需要绑定到相同的容器资源。所以就需要重载,这样使用相同名的组件就映射到不同的资源。 缓存引用的服务定位器将导致 J2EE 1.3(以及以后版本)中有重载资源名的应用程序工作不正常。这些程序可能部署成功并且表面上看起来运行正确,但当组件使用了错误的资源时将引起微妙的并且难以诊断的问题。这是因为服务定位器将缓存不论哪个组件首次使用时所重载的名称的资源。当不同的绑定组件使用相同的资源名的时候,这个组件将不能得到它所绑定的那个资源,它将得到在缓存中的资源,而这个资源就是第一个组件的资源。 服务定位器何时会出错 让我们一步步的通过这个过程来看看具体是在哪里出错: 在部署阶段,部署者绑定两个资源,如上文所述( 表 4)。 让我们从应用程序启动后说起,第一个用户是雇员并使用 EmployeeBean 访问数据库。 EmployeeBean 使用缓存服务定位器访问 jdbc/AccountDB 服务定位器没有在它的缓存中找到 jdbc/AccountDB,因为此时缓存是空的。 reference cache { }服务定位器执行 JNDI 查找并取得容器资源 jdbc/AccountEmployeeDS。服务定位器将这个资源添加到缓存中 jdbc/AccountDB 关键字下面: reference cache {jdbc/AccountDB jdbc/AccountEmployeeDS}服务定位器返回容器资源 jdbc/AccountEmployeeDS。 现在正如所预料的那样,EmployeeBean 中有了资源 jdbc/AccountEmployeeDS。 现在另外一个用户,一个顾客,开始使用应用程序,使用 CustomerBean 访问数据库。 CustomerBean 使用缓存服务定位器访问 jdbc/AccountDB: 此时,服务定位器在它的缓存中找到了 jdbc/AccountDB。 reference cache {jdbc/AccountDB jdbc/AccountEmployeeDS}服务定位器略过 JNDI 查找并取而代之的使用缓存中的资源。 服务定位器返回容器资源 jdbc/AccountEmployeeDS。 CustomerBean 现在拥有了资源: jdbc/AccountEmployeeDS。问题出现了: CustomerBean 现在拥有了 jdbc/AccountEmployeeDS,而不是它该拥有的 jdbc/AccountCustomerDS。 CustomerBean 现在使用错误的数据源。 检测缓存问题 当两个组件使用一个重载的资源名,也就是说,一个名称绑定到两个不同的资源,缓存服务定位器为两个组件返回相同的资源。这是一个非常微妙的错误,并且难以检测和诊断。 设想一下在我们的例子中错误的结果以及这是如何的难以诊断: 如果雇员先访问,客户取得了数据源,通过这个数据源他就可以访问机密数据表。这在功能测试中很难发现,特别地是在如果 Java 应用程序适当的组织了客户对某些专有数据的访问时。如果可以检测到这个问题,那么只是会偶尔在雇员先到的时候发生这样的错误。只有偶尔会发生的问题是很难确定问题的起因的。 如果客户先访问,那么就会使用客户数据源,雇员就不能访问机密数据表了。这个问题更加明显一些并且比较容易检测,但却很难解释。静态的代码分析清楚的显示了 EmployeeBean 使用雇员登录数据源。而且,只是偶尔发生问题。要花费多长时间解决当客户先访问时发生的问题呢?要解决由服务定位器导致的问题的难度有多大呢? 运行时证据 如果您正特别的寻找这个错误,那当然容易找到,就像您为正确的症状在正确的位置查找一样。我实现了两个无状态会话 bean 类,他们都通过相同的资源名访问数据源: jdbc/datasource。在 bean 访问过它的数据源后,打印出对象的 toString()。这段代码在两个 bean 里是相同的:
Servlet 创建每个 bean 的一个实例并且运行它。我也配置容器两个不同的数据源。当我部署我的应用程序时,我为每个数据源绑定一个 bean。 我的第一个实现没有使用服务定位器, bean 本身执行所有的 JNDI 代码。下面是我所得到的两个 toString() 的内容:
那么,上面的内容代表什么呢?类 com.ibm.ws.rsadapter.jdbc.WSJdbcDataSource 是专有的 WebSphere Application Server 类,实现 JDBC 数据源,这个类并不重要。重要的部分是在末尾的十六进制的数字,他们是实例对象标识符(OID)。 注意到两个 OID 不相同。这就显示两个 bean 使用两个不同的数据源。 我第二个实现使用了缓存服务定位器。JNDI 查找代码在服务定位器实现体内,实现缓存资源的功能。由于两个 bean 使用相同资源名: jdbc/datasource,所以服务定位器将缓存第一个查找并将其重用于第二个 bean。下面是输出结果:
注意到两个 OID 是相同的。由于缓存服务定位器的原因,两个 bean 现在使用相同数据源。第二个 bean 使用第一个 bean 的数据源, 而这恰恰是错误的。 我的第三个实现使用没有缓存的服务定位器。服务定位器代码两次查找资源,因为第一次查找没有被缓存起来。下面是输出结果:
这里的 OID 是不同的。因为没有缓存,每个 bean 都得到了正确的数据源。正如所预测的那样,重载的资源名和缓存服务定位器使得代码执行有不同的结果,它使某些组件取得错误的资源。 修改实现 我们已经看到了重载资源名和典型服务定位器实现,有资源缓存的集合,但他们之间并没有很好的合作。为何这样呢?更重要的是,我们可以修改它么? 为何缓存? 好,既然是由于缓存服务定位器导致重载资源名时的错误。我们为何又非得要缓存呢? 当首次使用 Service Locator 模式开发 J2EE 1.2 应用程序时,因为 JNDI 查找时常降低甚至有损于执行性能,所以缓存资源引用在当时是一个很好的主意。J2EE 容器提供商发现了执行性能方面的问题并在 J2EE 1.3 中改进了他们的实现。因此,对于 J2EE 1.3 来说,JNDI 查找执行的非常不错,而此时缓存查找就没有多大用处了。 不要只假设缓存服务定位器能显著的提高应用程序的性能,要使用性能测试来证明这一点。即使缓存能提高性能,当组件接收它所映射的资源失败时,也是一件痛苦的事情。“当然,组建取得了错误的资源当然不能正常工作,但是,要感谢缓存,它失败的 却是很快。”,执行迅速但不能正常工作的代码并不是好的。 缓存甚至不是 Service Locator 模式的主要点。Service Locator 的推动是创建简单、整洁的 API,以一种统一的方式来定位、访问其他服务和组建。缓存只是一种最优化。它是想要使定位器将相同的功能执行的更快。并不是要改变定位器的行为,结果 必须是相同的或没有缓存。无疑地,正如本文所展示的,缓存可以改变定位器的返回结果,因此就改变了应用程序的行为。 所以缓存并不是我们想要的。在正确的行为与快速的行为之间的抉择,正确性每次都会取得胜利。 为对象缓存的最好的方式是存储任何的它要在实例变量中使用的 JNDI 引用。每个实例必须初始化其自身的缓存,但它只缓存那些它要使用的引用,并且可以直接访问引用而不是要到一个散列映射中去寻找。试图努力避免取得重复的相同值总是一个很好的实践,即使对可以缓存的服务定位器来说也是这样。相反,只取得一次值,然后将其存储在一个变量中,以一个具有描述性的名称表示它。然后就可以在需要的时候访问这个变量。 为何重载资源名? 重载资源名使得服务定位器与其缓存之间变得混乱。除了去除缓存之外还有其他的选择么?为和不避免资源名的重载? 将每个组件的资源名绑定到容器的资源名是 J2EE 1.3 规范的一部分。一个不支持这点的应用程序就不是 J2EE 所允许的。应用程序在部署阶段必须支持资源名绑定。这意味着如果多个组件使用相同资源名的话,这个名称在部署时期就会被重载。 可选的解决方法 既然一个共享的资源名可以变成重载的,那么当我们使用缓存服务定位器时我们的组件仍然会接收到正确的资源,这又是为何呢?下面就是一些操作: 每个组件一个唯一的资源名 一个方法是确保每个组件使用唯一的资源名。通过那个方法,没有两个组件使用相同的资源名,因此就没有名称被重载。例如,EJB com.acme.AcmeEJB 使用容器资源 jdbc/datasource 可以实际的使用资源名称 jdbc/com/acme/AcmeEJB/datasource。由于每个 EJB 类都有一个唯一的包和类名,这种命名方法保证了每个组件的资源名将是唯一的。虽然这是一种很笨重的实现方法。当不同组件类型计划使用相同的资源时,这可以使得它们轻易的使用相同的资源名。每个组件类型一个唯一的服务定位器实例 另外一个方法是每个组件类型使用它自身的服务定位器实例,而不是集合。通过这个方法,每个特定类型的组件将得到其自身的缓存引用,而不会与任何其它组件缓存有冲突。然而,这实现起来很难。每个 Web 应用程序在何处存储它的要与其他 Web 应用程序和 EJB 类型有区别的服务定位器呢?对 EJB 类型来说,每个类可以为它的服务定位器声明静态变量,但 EJB 类的静态变量必须是只读的(因此就是 final 类型),这就要求重新设计服务定位器类,以使他的无参数构造器不抛出异常。而且,良好分解的 EJB 通常代表许多简单的 Java 对象,这些对象将不能知道要使用哪个服务定位器,然后可能要以某种方式调用 EJB 来取得。服务定位器作为集合的形式实现起来要简单的多。不要使用服务定位器 组件可以通过根本不使用服务定位器而避免重载缓存的名称的问题,但是这种方法又有点错杀一千的感觉。 Service Locator 模式对封装使用 JNDI 的代码仍然有用,即使定位器不使用缓存。如果把这个模式都全盘否定而失去了这个封装性,那将是一件很不幸的事。剩下的一个选择是使用服务定位器使用集合的方式,但是要去除引用缓存。将其应用于现有应用程序很简单:只要改变服务定位器实现去禁止或去除缓存。 在容器中缓存 最终,最好的回答是不在应用程序中缓存,而是缓存于容器当中。首先,这将对所有可以缓存的应用程序有用,不论它们是否使用 Service Locator 模式。其次,容器可以通过它们的容器名缓存资源,这些名称必须是唯一的因此它们就不会在任何单独的 J2EE 应用程序部署中被重载。 这只是恰巧发生在 WebSphere Application Server 缓存 JNDI 引用结果时。更多的细节请参见 WebSphere Application Server Information Center(参加 参考资料)。 正如前文所述,每个对象也可以缓存它在实例变量中使用的 JNDI 引用,所以每个对象在某一时刻只能访问一个资源。 结束语 重载资源名实际开始于 J2EE 1.3。组件通常共享资源名,部署者可以映射组件并使其对不同容器资源共享其名称。带有资源缓存的集合服务定位器创建全局缓存,通过这种方式不能为重载的资源名正确处理组件级映射。 简单的结论是:使用服务定位器进行缓存不是一个好的主意。包含缓存服务定位器的应用程序迟早要出问题,而且这个问题将很难检测、很难再现且很难诊断。毫无疑问会发生问题,而且我可以保证:只要在部署阶段为不同的资源绑定相同的资源名,这个问题就会发生。 希望为组件使用相同的资源,共享相同的资源名仍是一个好主意。同样,使用服务定位器封装资源访问、以集合的形式使用服务定位器也是一个不错的想法。但是服务定位器不应包含资源缓存。 (责任编辑:admin) |
