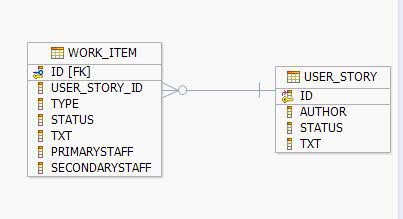
IBM Data Studio 是一款免费的基于 Eclipse 的用于数据库开发的工具。 IBM Data Studio 包含了开发数据库存储过程的所有功能,同时提供了对 DB2 v9 的 XML 功能的支持。 本文将通过一个开发实例介绍 IBM Data Studio 是如何帮助我们进行存储过程开发的。 项目实例介绍 在开始使用 IBM Data Studio 之前,让我们先来了解一下本文的项目实例。该项目实例是一个简化版的软件开发管理系统。系统主要管理 User Story 和 Work Item 的信息。 User Story 就是以用户的角度编写的业务需求,是软件需要实现的功能。我们需要记录 User Story 的具体内容和其状态。这里的状态是指该 User Story 是在草拟状态还是完成状态。 Work Item 用于记录软件开发的过程。 Work Item 可以是根据某个 User Story 编写的详细设计,也可以是一个编码任务,或者是一个 bug 报告。我们需要记录其状态(未分配,处理中和完成等),结对编程人员的 Email 等信息。 本系统应该实现如下功能 ( 未列出所有功能 ): 创建 User Story 。 修改 User Story 。 查询所有草拟状态的 User Story 。 创建 Work Item 。 修改 Work Item 。 查询属于某个 User Story 的所有 Work Item 。 为此我们设计了相应的数据库表:USER_STORY 和 WORK_ITEM 。它们的详细定义如下表所示: 图 1. User story 和 Work item 的关系
表 2. Work Item 的定义
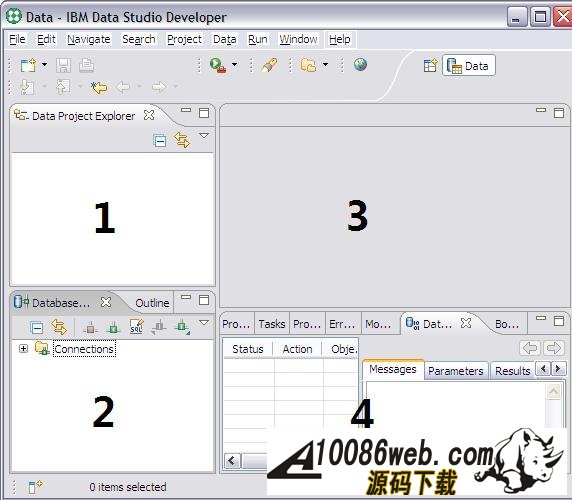
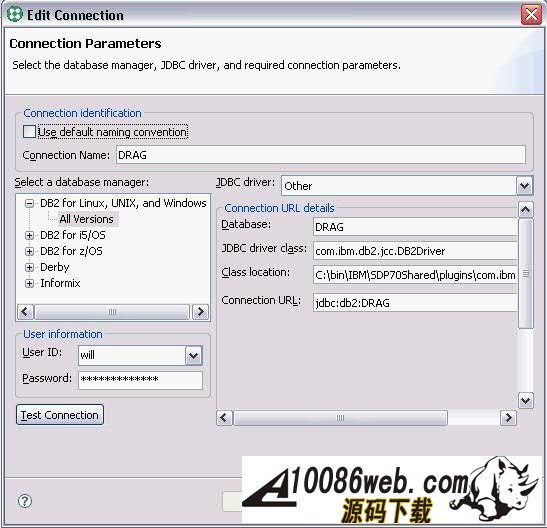
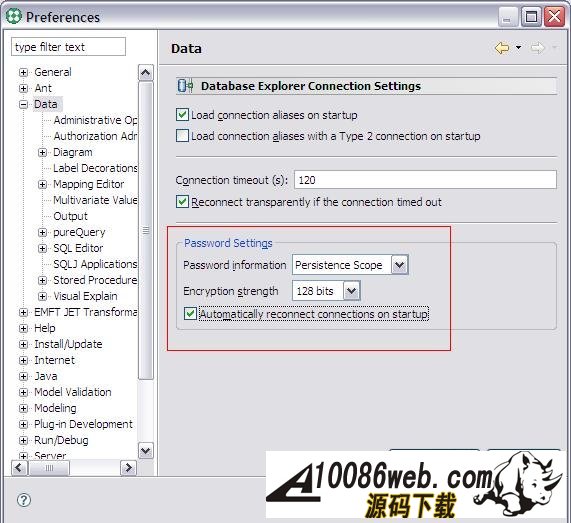
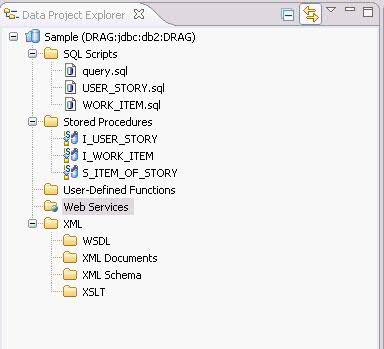
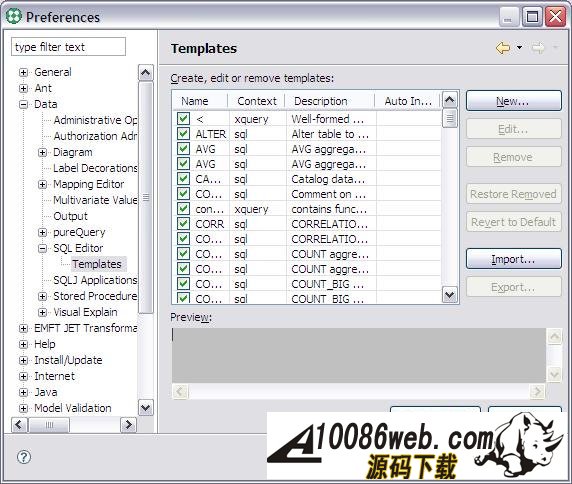
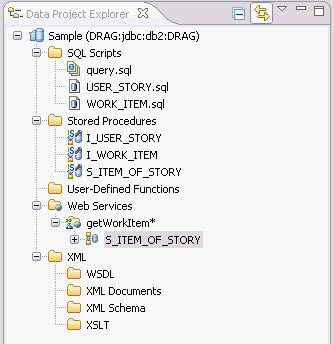
为了实现系统的功能,我们还需要下列存储过程 : I_USER_STORY: 创建 User Story 。 U_USER_STORY: 修改 User Story 。 S_INIT_STORY: 查询所有草拟状态的 User Story 。 I_WORK_ITEM: 创建 Work Item 。 U_WORK_ITEM: 修改 Work Item 。 S_ITEM_OF_STORY: 查询属于某个 User Story 的所有 Work Item 。 DB2 存储过程开发 “工欲善其事,必先利其器”。现在我们明确了需求,为了开发出优秀的软件,我们还需要一个开发工具。 IBM Data Studio 就是一款非常好的存储过程开发工具,我们可以从 IBM 官方网站上下载其安装包。安装完毕后启动 IBM Data Studio,可以看到 IBM Data Studio 的界面主要由四个区域组成: Data Project Explorer中会列出所有的Data project。 Data Explorer中会列出所有的数据库连接。 工作区用于编辑 SQL 文件和存储过程源文件。 Data Output是结果输出区,在我们执行 SQL 语句后,数据库返回的结果会显示在该区域。 图 2. IBM Data Studio 的主要界面 创建数据库项目 首先创建一个数据库连接: 右键单击Data Explorer中的Connections, 选择New Connections..., 在新建数据库连接向导中,填入数据库的信息 : 数据库地址,端口,用户名和密码等, 单击Test Connection按钮来测试数据库连接是否正常, 单击Finish按钮后,一个新的数据库连接就创建完毕。我们可以在Data Explorer中看到新建的数据库连接 DRAG 。 图 3. 新建数据库连接 默认情况下 IBM Data Studio 不会记录连接数据库的用户密码,为了避免每次连接数据库时都输入密码,我们可以修改相应设置,把数据库的用户和密码存储在电脑中: 从菜单上选择Window > Preferences..., 在弹出窗口的左边选定Data节点, 把Password information设置为Persistence Scope。 图 4. 修改密码保存选项 接着,我们创建一个数据库项目。 右键单击Data Project Explorer,在弹出菜单上选择New > Data Development Project。 输入项目名称和 schema 名称。这里我们输入 Sample 作为项目的名称,使用登录用户 ID 作为项目的 schema 。 选择数据库连接。您可以创建一个新连接,也可以使用已有的数据库连接。这里我们选择数据库 DRAG 。 点击Finish,一个 Data Development Project 就创建完毕了。 展开 Sample 项目,我们可以看到在项目的根目录下有五个文件夹,分别用来存放 SQL 文件,存储过程源文件,UDF 源文件,Web Service 文件和 XML 文件。 图 5. 项目的结构 开发数据库对象 创建完项目,我们就可以开始开发数据库对象了,也就是要编写建表语句和存储过程。为了规范我们编写的代码和提高我们编码的效率,我们首先要设置一下模板。 在 IBM Data Studio 中可以很方便地定义 SQL 模板: 选择菜单Window > Preferences。 在弹出的参数配置页面的左侧,选择Data > SQL Editor > Templates。 从下图我们可以看到,IBM Data Studio 给我们提供了一些通用的模板。 图 6. 通用模板 这里我们再定义一些我们项目中使用的模板。 点击New...按钮,IBM Data Studio 会弹出一个模板定义窗口。 输入模板的名称和内容 (Pattern) 等。在定义模板内容的时候,需要替换的部分我们称为变量,变量可以使用 ${} 进行定义,例如 ${expression} 。 下面是我们定义的模板的具体内容: 清单 1. 创建表的模板
清单 2. 创建存储过程的模板
现在我们开始编写代码。右键单击SQL Scripts文件夹,在弹出菜单中选择New > SQL or Xquery Script。输入名称 USER_STORY,然后单击Finish。在打开的 USER_STORY.SQL 中,单击右键选择Content Assist,然后选择 create table 模板。模板的内容被插入到文件中,需要修改的内容被高亮显示。我们依次修改表名和列的信息。在我们修改 SQL 文件的时候,IBM Data Studio 还在有语法错误的语句下面显示一条红线,真是太棒了! 修改后的代码如下: 清单 3. 建表语句
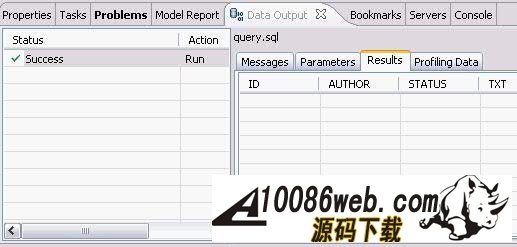
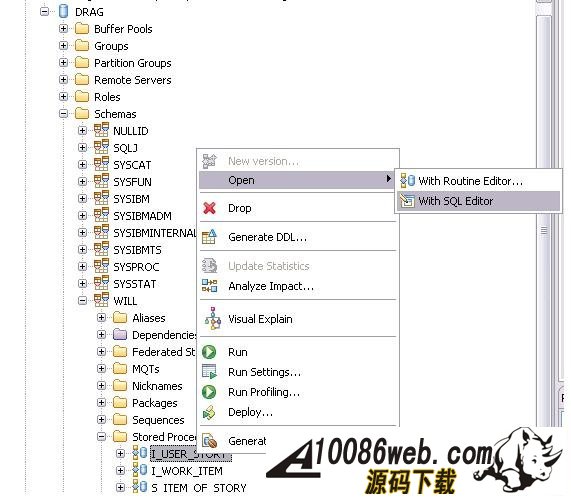
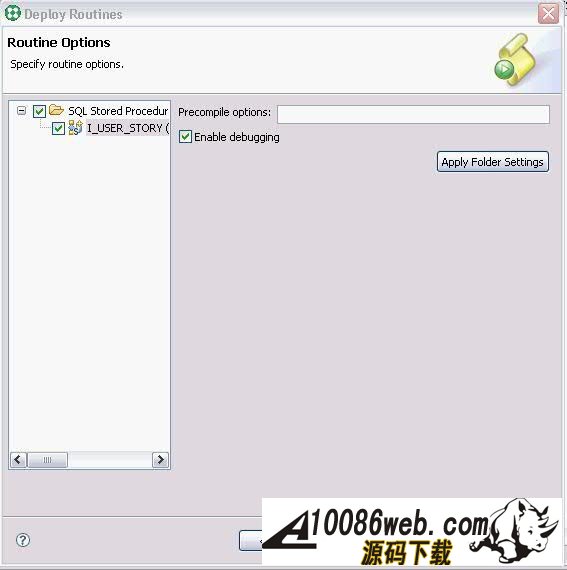
编写完建表文件后,我们需要把它装载到数据库中。 由于我们在 USER_STORY.SQL 文件中使用 @ 符号作为分隔符。所以,我们需要在 IBM Data Studio 中把 @ 指定成分隔符。在工作区,单击右键,在弹出菜单中选择Set Statement Terminator,然后输入 @ 。 下面,我们开始执行我们编写的 USER_STORY.SQL 文件。右键单击工作区,选择Run SQL。我们可以在Data Output视图中看到 Run successful 的消息。 我们来查询一下 USER_STORY 表里数据。新建一个 query.sql 文件。在 query.sql 文件里键入 SELECT * FROM, 这时我突然忘记了表的名字(有时候,因为表名太长,我们很容易不记得其名字),IBM Data Studio 可以帮助我们找到我们想要的表。首先键入 U (我记得表是以 U 开头的),然后单击右键选择Content Assist或者使用快捷键 Alt+/ 。哦,IBM Data Studio 把所有以 U 开头的表都列在了弹出框里。我们选择 USER_STORY 这个表。然后,我们象执行 USER_STORY.SQL 一样执行该语句,可以在 Data Output 视图中看到,目前表里没有任何数据。 图 7. Data Output 视图 在Content Assist和模板的帮助下,我们很方便的完成了项目所需要的表和存储过程。虽然 IBM Data Studio 也提供了创建存储过程的向导,不过我更倾向于模板加手动修改源文件的方式编写存储过程。您可以选择您自己喜欢的方式去编写存储过程。 有时候,我们需要看一下数据库中某个存储过程的源代码。我们可以在Database Explorer中,依次打开[database name]> Schemas > Stored Procedures。右键单击存储过程,在弹出菜单中选择Open > With SQL Editor。然后存储过程的源代码就在 IBM Data Studio 中打开了。 图 8. 打开源代码 调试存储过程 我们已经编写完所有的存储过程了,测试人员正在对这些存储过程进行测试,初步结论是这些存储过程运行正常。我们非常高兴,认为开发工作应该是完成了。可是正当我们暗自高兴的时候,测试人员来找我们了。他们说,新增 User Story 这块功能突然出问题了,这块功能在前几天的测试都是正常的。这就奇怪了,我们最近没有更新过代码,为什么原来可以使用的功能突然就不能用了呢? 大家一边看着代码,一边皱眉---代码应该没有问题啊。 幸好,IBM Data Studio 为我们提供了非常优秀的调试功能,我们可以像调试 Java 程序那样调试存储过程。 在 IBM Data Studio 中针对存储过程设置断点,单步执行,查看存储过程运行时的某些变量值都变得非常简单。 现在我们就开始调试出问题的存储过程 I_USER_STORY 。 在Data Project Explorer窗口中,右键单击存储过程 I_USER_STORY,选择Deploy..., 在弹出的部署向导页上选中Enable Debuging选项,点击Finish,把 I_USER_SOTRY 部署到数据库中, 使用 SQL 编辑器打开项目中的存储过程,双击左侧栏设置断点。 在Data Project Explorer窗口中右键单击存储过程,选择弹出菜单中的Debug...。 IBM Data Studio 询问我们是否使用调试视图,选择Yes。 在调试视图中,我们可以点击 Debug 窗口中的step into,step over进行单步调试,可以在Variables窗口看到当前所有变量的值。
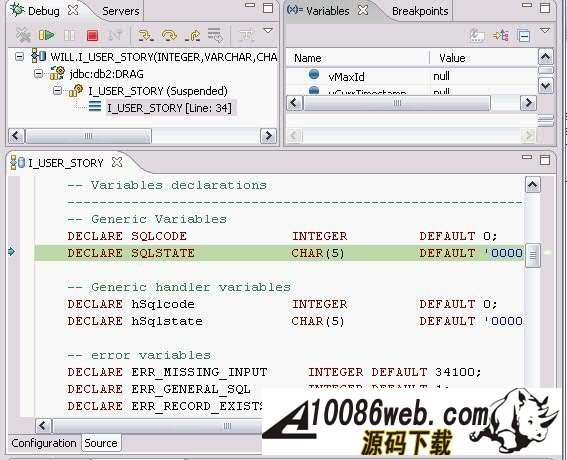
通过单步执行,我们很快的就找到了出错的代码: 清单 4. 出错的代码
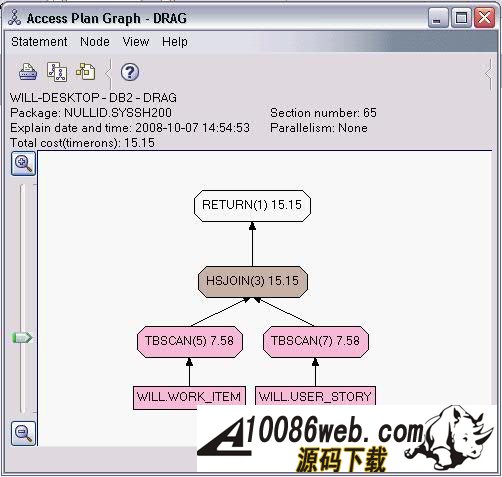
原来,我们把 vMaxId 声明成 SMALLINT, 然而随着表 USER_STORY 中数据的增加,MAX(ID) 很快就超过了 SMALLINT 的最大值,这时我们再把 MAX(ID) 赋值给 vMaxId,就会出现溢出的错误。看来 I_USER_SOTRY 中有一个 bug 。我们应当把 vMaxId 声明成 INTEGER 而不是 SMALLINT 。我们把修改后的代码重新部署到数据库中后,测试人员高兴的告诉我们,新增 User Story 又重新可用了。 多亏 IBM Data Studio 的调试功能,使得我们很快的找到并修改了 bug 。 分析存储过程性能 我们的系统顺利的通过了功能测试,接下来我们要面临性能测试的考验了。 在性能测试时,测试人员抱怨说,在查询 Work Item 的时候,系统的性能特别差。为了解决性能问题,IBM Data Studio 为我们提供了 Visual explain 。 Visual explain 可以帮助我们编写出高效率的 SQL 语句。这对于存储过程的性能调优非常重要。 IBM Data Studio 可以为我们提供图形化的执行计划:在 SQL 编辑器中选中你需要分析的 SQL 语句,单击右键,选择Visual Explain,然后我们就得到了如下图所示的 SQL 执行计划。 图 11. SQL 执行计划 通过查看 Visual Explain,我们得出结论:由于 WORK_ITEM 表中的数据太多,对全表扫描花费太多的时间,我们应该建立合适的索引来提高性能。建立完索引后,我们再次执行 Visual Explain 。现在,其性能就提高了很多。 当然,本文中的例子只有两个表,略显简单。在实际项目中,我们往往需要查询多个表,查询条件也会非常复杂。通过 Visual Explain 我们可以获得 SQL 语句是否使用了索引,是否对某个表进行了多次扫描等信息。这些信息对优化我们的 SQL 语句非常有用。 Data Web Service 我们的系统经过严格的测试后,终于上线了。用户对我们的系统非常满意。但是他们提出了一个要求,希望我们的系统可以跟他们另外的一个业务系统进行集成。那个业务系统需要获得 Work Item 的信息,但是它不能直接调用我们的存储过程。经过讨论,我们决定把我们的存储过程发布成 Web Service,以方便其业务系统的访问。 使用 IBM Data Studio,我们可以很方便的把存储过程发布成 Web Service 。 右键单击项目中的文件夹,选择New Web Service...。 在弹出的页面中输入 Web Service 名称 getWorkItem,点击Finish。 把 Stored Procedures 文件夹下的 S_ITEM_OF_STORY 拖到 Web Service 文件夹下的 getWorkItem 上,这样一个 Web Service 就构建完成了。 图 12. 创建 web service 下面我们把这个 Web Service 到出为 war 包。 右键点击 Web Service 文件夹下的 GetTasks,选择Build and Deploy..., 在弹出的向导页面中,指定 web server 的类型和 web service 的类型,点击Finish, 完成 war 包的导出。 图 13. 导出 war 包 结束语 文中的例子虽然简单,但是包含了开发存储的各个方面。可以看出 IBM Data Studio 对存储过程的开发的支持是非常全面的。 IBM Data Studio 还提供了很多有用的功能,例如:通过图形方式生成 SELECT 语句,可以生成存储过程的 Unit Test 程序等等。相信读者在使用 IBM Data Studio 的过程中会不断发现一些非常有用的功能。希望本文能促使您开始使用 IBM Data Studio,并且享受 IBM Data Studio 给我们带来的开发存储过程的便利。 本文示例源代码或素材下载 (责任编辑:admin) |