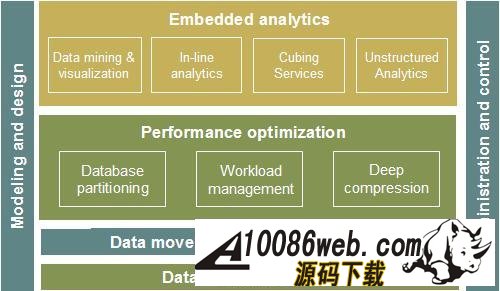
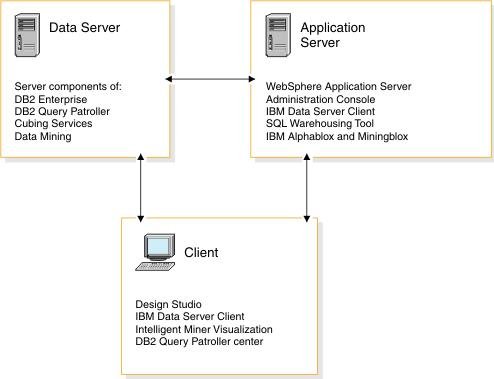
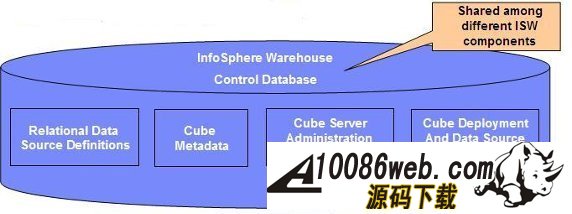
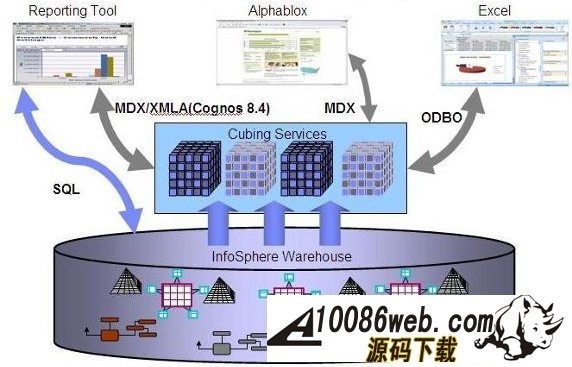
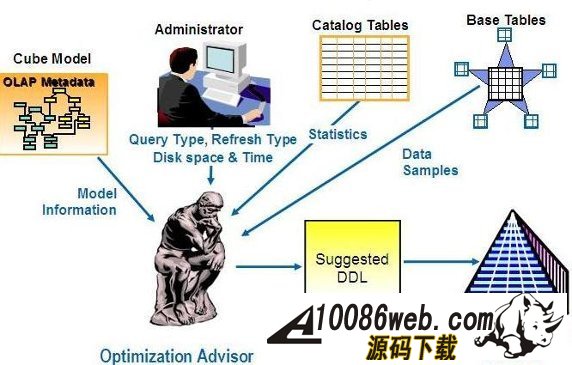
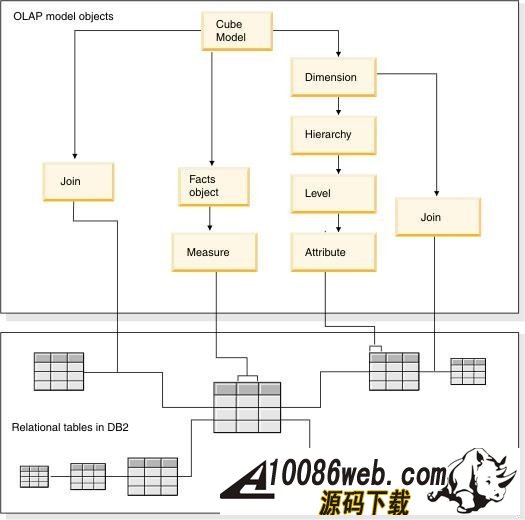
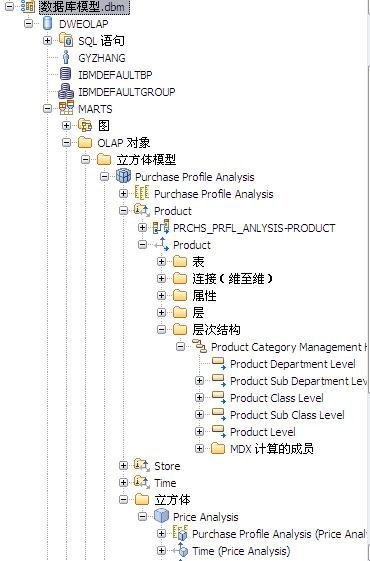
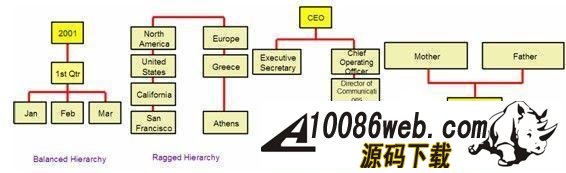
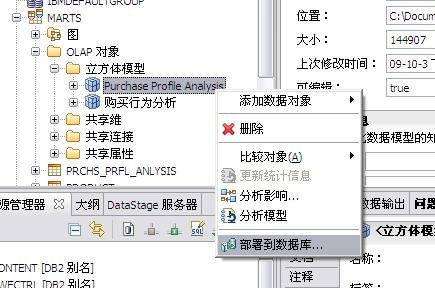
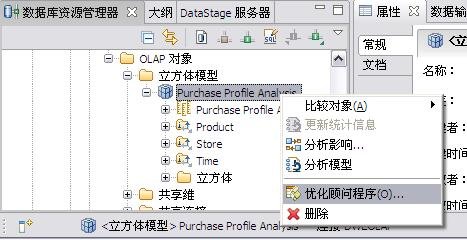
InfoSphere Warehouse 软件包是一个集成的解决方案,它包括了实现一个数据仓库应用所需的各种功能部件,如下图所示: 图 1. 显示了 InfoSphere Warehouse 软件包组件 它主要包括: InfoSphere Warehouse SQL Warehousing Tool,用于数据抽取、转换、清洗、装载,它主要实现基于数据库的数据转换工作。 InfoSphere Warehouse Cubing Services,它主要完成构建多维数据模型,并将多维数据模型保存到数据库中,使数据库成为真正的多维模型感知的数据库系统,它还可以针对多维数据模型提供优化功能,通过提供建立数据汇总表的功能来优化数据分析效率。另外,Cubing Services Cube Server 提供一个高效、可扩展的多维立方体服务器引擎,支持大量用户对不同多维立方体的访问。 InfoSphere Warehouse Intelligent Miner,用于数据挖掘的功能部件,它通过 Modeling、Visualization 及 Scoring 等功能实现数据挖掘模型的建模、可视化展现及实时利用模型为新数据评分的功能。Mining 功能部件提供了业界丰富的数据挖掘算法,并实现了将数据挖掘功能嵌入到工作流应用中,扩展了数据挖掘应用的应用范围。 DB2 EntERPrise Server Edition,提供了数据仓库数据存储功能,它提供了业界领先的数据可扩展能力,可以支持 TB 级海量数据仓库系统,并通过查询并行能力、优化器算法、MQT 汇总表等方式来提高查询的效率。 InfoSphere Warehouse Design Studio,提供了集成的、基于 Eclipse 的数据仓库设计工具,它可以实现数据仓库抽取流程的设计、挖掘模型的设计、多维分析建模。 InfoSphere Warehouse Administration Console,,提供了统一的、集成的数据仓库管理工具,它是一个基于 Web 界面的管理工具,可以完成数据抽取流程的管理、调度,多维模型的管理及优化,挖掘模型的管理及前端分析工具 Alphablox 的管理。 DB2 Query Patroller,用于数据仓库负载管理 IBM Alphablox, 用于查询、报表及 OLAP 分析的前端展现工具,它是一个基于 J2EE 架构的多维分析工具,主要定位于提供嵌入式的、可定制化的应用。用户开发 Alphablox 应用,主要是开发一些 JSP 页面,同时嵌入 Alphablox 提供的用于多维分析的各种 Blox,开发周期短,可定制能力强。 InfoSphere Warehouse 文档 WebSphere® Application Server 应用服务器,WebSphere Application Server 是一个基于 Java 的 Web 应用程序服务器,它是管理控制台所必需的。WebSphere Application Server 提供功能众多的应用程序部署环境及一组完整的应用程序服务,包括用于事务管理、安全性、集群、性能、可用性、连接和可伸缩性的功能。 Infosphere Warehouse 软件包主要可以分为三个部分功能组件,在实际软件部署时,我们可以将这三个部分功能组件安装在一台机器上,也可以将这三个部分功能组件安装在不同的机器上。这三个功能部件如下图所示: 图 2. 显示了 InfoSphere Warehouse 三个功能部件 InfoSphere Warehouse数据服务器: DB2 企业服务器版 Intelligent Miner DB2 Query Patroller InfoSphere Warehouse应用程序服务器: 管理控制台和 Workload Manager SQL 仓储(SQW)管理 Cubing Services 管理 智能挖掘管理 Workload Manager 非结构化文本分析 IBM 数据服务器客户机 WebSphere Application Server Cubing Services 立方体服务器 挖掘 Blox InfoSphere Warehouse客户机: Design Studio SQL 仓储(SQW)工具 Cubing Services 建模 智能挖掘工具 非结构化文本分析工具 挖掘 Blox 工具 IBM 数据服务器客户机 DB2 Query Patroller 中心 Intelligent Miner Visualization Cubing Services 客户机 管理控制台命令行客户机 下边,我们通过一个简单的“Purchase Profile Analysis”的例子来介绍一下如何利用 Infosphere Warehouse 功能部件及 Cognos 快速建立数据分析应用。 环境准备 本次实验环境,我们采用 Windows XP 操作系统,安装了如下的软件,并且所有软件安装在同一台机器上: IBM InfoSphere Warehouse 9.5.2 Cognos BI Server 8.4 Cognos BI Model 8.4 IBM HTTP Server 7.0 逻辑模型设计 “Purchase Profile Analysis” 模型主要用来进行购买行为分析,它包括 3 个维度: Product 维度:产品维度,包括 Product Department Level, Product Sub Department Level, Product Class Level, Product Sub Class Level, Product Level 五个层次; 设计时定义了 Calendar Year Hierarchy查询路径,包括:Product Department Level, Product Sub Department Level, Product Class Level, Product Sub Class Level, Product Level 五个层次。 Store 维度:地区维度,包括 Organization Unit Sub Division Level,Organization Unit Region Level,Organization Unit District Level,Organization Unit Store Level 四个层次; 设计时定义了 Organization Unit Store Hierarchy查询路径,包括:Organization Unit Sub Division Level,Organization Unit Region Level,Organization Unit District Level,Organization Unit Store Level 四个层次。 Time 维度:时间维度,包括 Calendar Year Level,Calendar Year-Quarter Level,Calendar Year-Quarter-Month Level,Day of Calendar Month Level,Fiscal Year Level,Fiscal Year-Quarter Level,Fiscal Year-Quarter-Month Level 六个层次; 设计时定义了两个查询路径: Calendar Year Hierarchy路径包括:Calendar Year Level,Calendar Year-Quarter Level,Calendar Year-Quarter-Month Level,Day of Calendar Month Level 四个层次; Fiscal Year Hierarchy路径包括:Fiscal Year Level,Fiscal Year-Quarter Level,Fiscal Year-Quarter-Month 三个层次。 事实定义了如下量度:
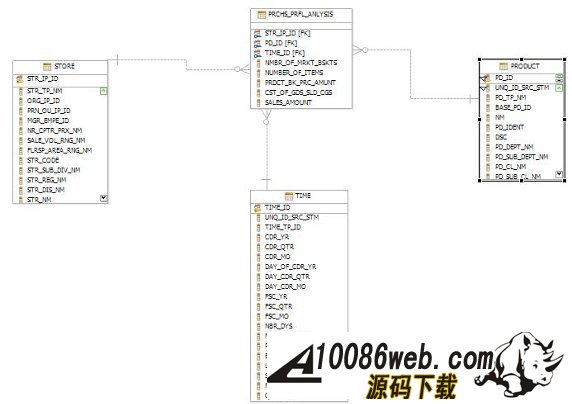
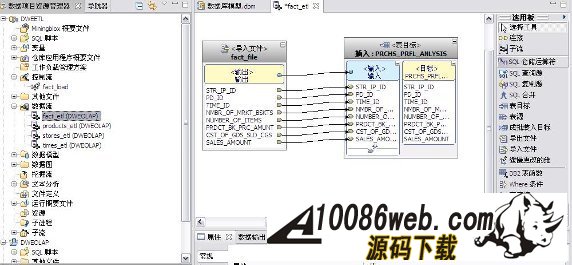
在数据库中建立星型模型 当定义好多维逻辑模型后,我们要在数据库中实现其物理模型。通常情况下,基于关系型多维分析往往采用星型模型或雪花型模型。这里,我们建立了一个简单的星型模型,如图所示: 图 3. 显示了我们定义的星型模型 我们定了 TIME,STORE,PRODUCT 三个维表及 PRCHS_PRFL_ANLYSIS 事实表。 在 InfoSphere Warehouse 中,我们建议星型模型的事实表及维表之间要建立主外键关系或者 informational constraint,这样,特别是对多维模型优化会起到重要作用。 我们首先创建一个数据库 DWEOLAP,用于存储分析数据及多维模型,并在 DWEOLAP 中创建星型模型的表:
其中,schema.db2 文件脚本内容为:
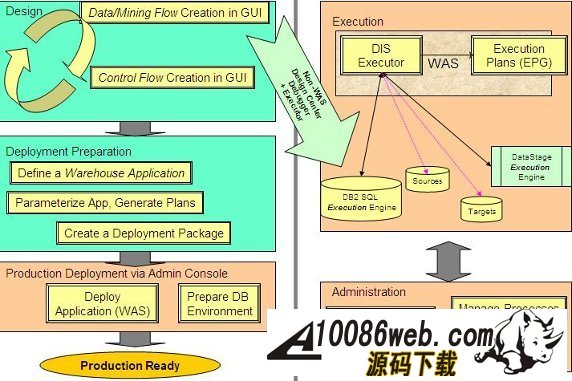
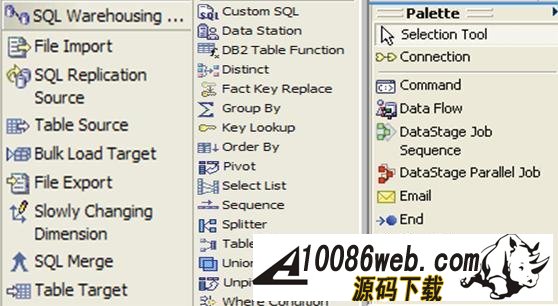
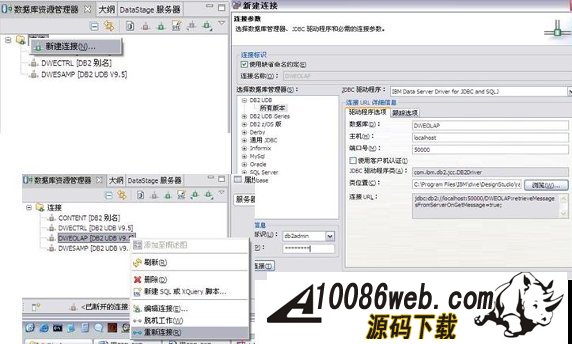
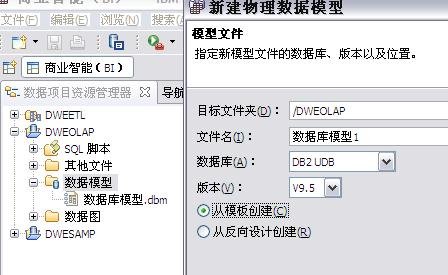
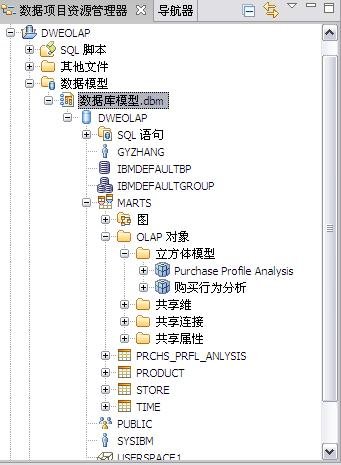
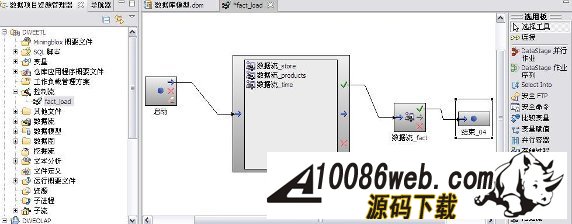
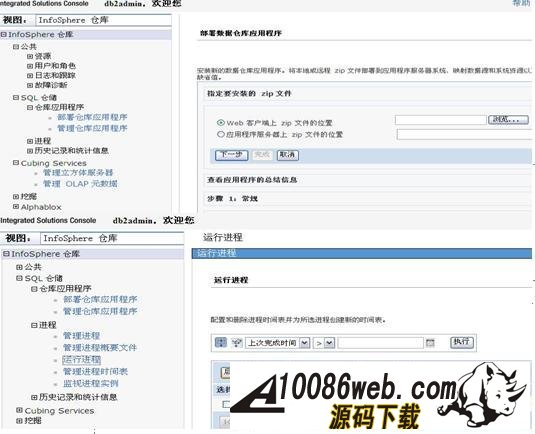
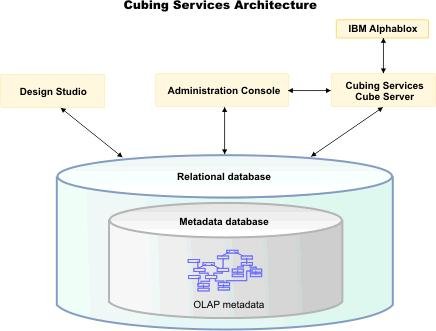
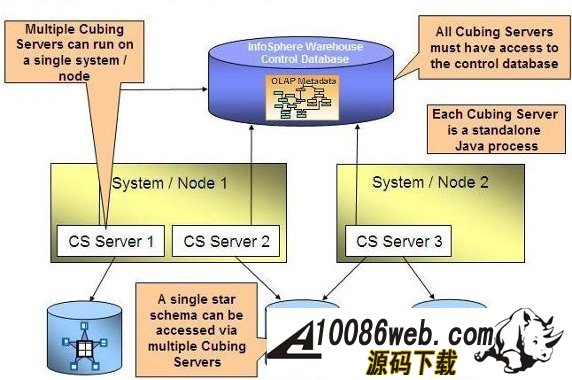
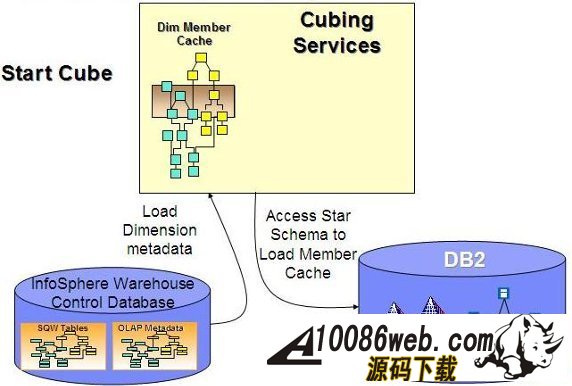
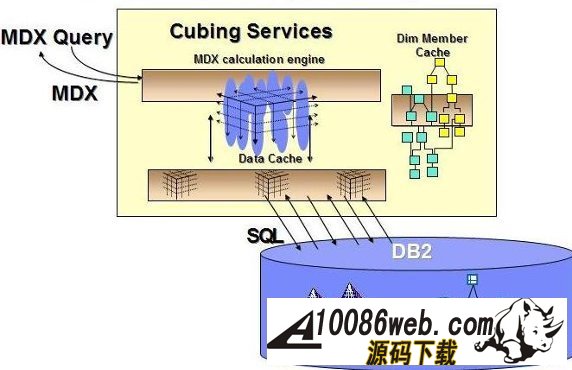
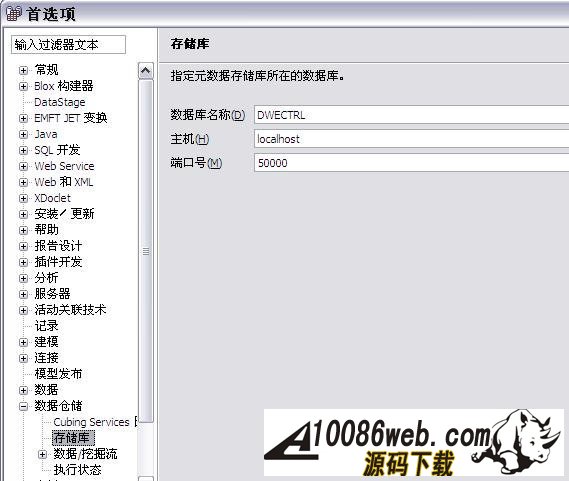
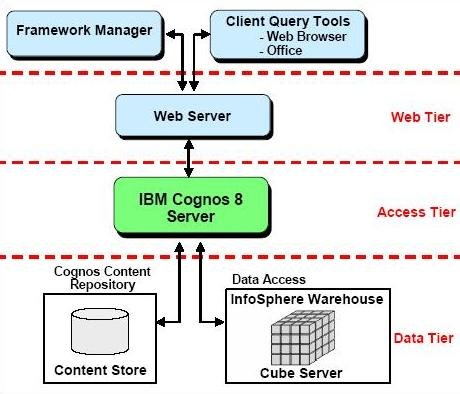
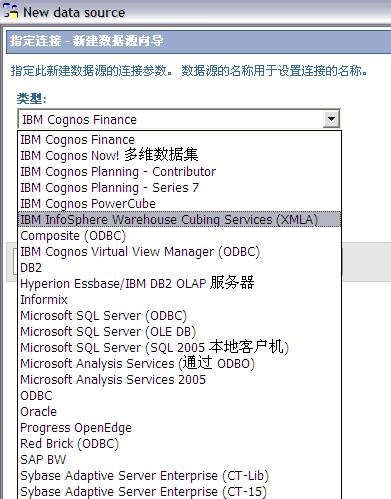
用 SQL Warehouse 完成数据抽取、转换、装载工作 当在 DWEOLAP 数据库中创建好星型模型后,下边就要完成数据抽取、转换、装载工作,我们这里通过 Infosphere Warehouse 组件中的 SQL Warehouse 来完成。 采用 SQL Warehouse 来完成数据抽取、转换、装载工作的主要步骤包括: 在 Design Studio 中创建数据设计项目,用来创建数据物理模型,在 SQL Warehouse 中,数据的抽取、转换是要针对物理模型来完成的。 在 Design Studio 中创建数据仓库项目,并关联相应的数据设计项目,来指定相应的物理模型。SQL Warehouse 设计数据的抽取、转换流程都是在数据仓库项目中完成的。 在 Design Studio 中设计数据流程,完成数据的抽取、转换及装载工作。 在 Design Studio 中设计控制流程,完成数据流程的控制。在 SQL Warehouse 中,ETL 流程的调度、运行都是基于控制流程来完成的。 在 Design Studio 生成数据仓库应用程序,为 ETL 流程的部署做准备。 在 Admin Console 数据仓库管理工具中,部署 ETL 的控制流程,并实现 ETL 流程的调度及运行,即日常的运行工作。 图 4. 显示了 SQL Warehouse 的基本工作流程 SQL Warehouse 提供 GUI 界面来完成 ETL 流程的设计及运行工作,我们在设计时,只需要鼠标的拖拽工作就可以完成大部分开发工作。SQL Warehouse 中提供了大量的数据转换功能函数,使数据转换工作变得更见简单。 图 5. 列举了一些典型的数据转换功能函数 首先,我们在数据库资源管理器中创建一个数据库连接并连接数据库 DWEOLAP,如下图所示: 图 6. 在数据库资源管理器中创建一个数据库连接 创建一个数据设计项目 DWEOLAP,创建物理数据模型并通过逆向工程获得 DWEOLAP 数据库模型,如下图所示: 图 7. 获得 DWEOLAP 数据库模型 通过逆向工程,我们得到如下数据库模型,如下图所示,每一个模型对应一个数据库: 图 8. 显示了 DWEOLAP 数据库模型 接下来,我们创建数据仓库项目 DWEETL,并关联数据设计项目 DWEOLAP。 在 DWEETL 项目中创建数据流 stores_etl,times_etl,products_etl,fact_etl 分别用来从文本文件中装载 store,time,product 维表数据以及 prchs_prfl_analysis 事实表数据。如下图所示: 图 9. 创建数据流 fact_etl 当创建完数据流后,我们要在 DWEETL 项目中创建控制流 fact_load,如下图所示: 图 10. 创建控制流 fact_load 在创建 fact_load 控制流时,我们将数据流 stores_etl,times_etl,products_etl 放在一个并行容器中,这样,数据流 stores_etl,times_etl,products_etl 可以并行运行,同时,只有当数据流 stores_etl,times_etl,products_etl 都完成后,才可以运行下边的 facts_etl 数据流,这也是星型模型所要求的,将所有维表装载完成后,再装载事实表。 创建完相应的控制流后,我们要在 Design Studio 中创建数据仓库应用程序,为部署数据抽取程序做准备。如下图所示,我们选择“仓库应用程序概要文件”条目,点击右键,选择“新建数据仓库应用程序”,我们将生成一个数据仓库应用程序包,以 Zip 文件形式保存在我们指定的目录中,即:c:\tmp\DWEETL.zip 文件。 图 11. 生成数据仓库应用程序包 接下来,我们要在 Admin Console 中,部署数据仓库应用程序,并运行或调度相应的控制流。如下图所示,我们选择“SQL 仓库“条目下的”部署仓库应用程序“来部署 DWEETL.zip 数据仓库程序,并选择“SQL 仓库“条目下的”进程“条目下的“运行进程”来运行或调度我们部署的仓库应用程序。当 fact_load 控制流运行成功后,我们便将数据装载到了定义的星型模型的表中。 图 12. 部署数据仓库应用程序 通过 Cubing Services 功能部件建立多维分析模型并创建立方体服务器 IBM InfoSphere Warehouse Cubing Services 用来提供基于关系型多维分析,即 ROLAP(Relational Online Analytical Processing)分析。如下图所示,IBM InfoSphere Warehouse Cubing Services 体系结构主要涉及 OLAP 元数据、Cubing Services Cube Server、Design Studio、Administration Console 等组件。 图 13. Cubing Services 体系结构 IBM InfoSphere Warehouse Cubing Services 用来提供基于关系型多维分析,即 ROLAP(Relational Online Analytical Processing)分析。通过 Cubing Services ,我们可以创建、编辑、导入、导出、部署多维分析模型。Cubing Services 同时提供优化技术,通过创建物化查询表 MQT(Materialize Query Table)来极大提高 OLAP 分析的性能。 在 Cubing Services 中,所有的多维立方体的元数据都集中保存在一个统一的 InfoSphere Warehouse control database 数据库中,缺省叫 dwectrl 数据库。它包含一些列的表,这些表的模式为 dwerepos,它保存了关系数据源的定义,立方体元数据,Cube Server 管理属性,立方体同数据源映射信息。如下图所示: 图 14. Cubing Services 元数据数据库 Cubing Services 元数据保存在关系数据库中,可以被 Cubing Services Cube Server, Design Studio 及 Administration Console 同时进行读写访问,也保证了元数据的一致性。Cubing Services 元数据数据库可以支持多个 cube servers 的同时访问,同时,可以支持关系数据库所具有的事务完整性、集成备份及恢复、数据库复制等特性。 Cubing Services Cube Server 是一个高性能、高可扩展性的立方体服务器引擎,OLAP 立方体模型都需要在立方体服务器中运行。同一个立方体服务器引擎可以支持多个 OLAP 立方体模型。通过立方体服务器引擎,我们可以支持大量用户对不同 OLAP 立方体的高效访问。 图 15. Cube Server 部署示意图 如上图所示,每一个 Cubing Services Cube Server 是一个独立的 java process, 运行在自己的 JVM 中,我们可以通过采用 64 位的 JVM,来进一步提高 Cubing Services Cube Server 的性能。在一台机器上,我们可以创建多个 Cubing Services Cube Server;每一个 Cubing Services Cube Server 可以同时支持多个 OLAP 立方体;多个 Cubing Services Cube Server 可以访问同一个星型模型。 Cubing Services Cube Server 依赖关系数据源来保存多维立方体所需要的基础数据及汇总数据。当执行多维分析查询时,会将需要的数据装载到 cube server 内存中。当 cube server 启动时,它会装载我们所定义的同 cube server 一同启动的所有立方体。对于每一个启动的立方体,Cubing Services Cube Server 会读取 Infosphere Warehouse Control Database 数据库中定义的相关维定义元数据,包括维定义及其层次信息、维成员、多维模型和关系数据库表及列的映射关系,并从数据源中的星型模型中装载维成员数据到 Cube Server 内存中。 如下图所示: 图 16. Cube Server 启动示意图 当用户发起多维分析查询时,Cube Server 通过读取星型模型或 MQT 中的数据装载到 Cube Server 中的数据缓冲区,构造虚拟立方体来执行相应的查询,如下图所示: 图 17. Cube Server 运行示意图 Cubing Services Cube Server 支持业界标准的 OLAP API(s) 包括 MDX,ODBO 及 XMLA。OLAP 前端分析工具可以通过上述 API 来进行多维查询及分析。如下图所示: 图 18. Cube Server 查询接口示意图 我们通过 MDX 来支持 Alphablox 前端分析工具 我们通过 ODBO 来支持 Microsoft Excel 进行多维查询分析。该功能是从 Infosphere Warehouse 9.5.1 开始提供的功能。 我们通过 XMLA 来支持 Cognos8.4 进行多维查询分析。该功能是从 Infosphere Warehouse 9.5.2 开始提供的功能,支持 Cognos 8.4 或更高的版本。 Design Studio 用来构造多维模型、建立多维模型元数据同关系数据库的映射关系。我们可以使用 Design Studio 来创建、修改立方体模型及相应元数据,包括事实、维、维层次、属性及连接关系。当多维模型创建及验证后,我们可以将其部署到 InfoSphere Warehouse 元数据数据库中。当多维模型部署后,我们可以使用 Cubing Services optimization advisor 来分析模型,创建相应的 MQTs 来优化立方体查询效率。 使用 Design Studio,我们可以: 设计、创建并编辑元数据 从 Data Project Explorer 中部署多维元数据到 InfoSphere Warehouse 元数据数据库中 导入元数据到 InfoSphere Warehouse 元数据数据库中或 Data Project Explorer 中 从 InfoSphere Warehouse 元数据数据库中删除多维模型 导出元数据到文件中 通过逆向工程将 InfoSphere Warehouse 元数据到 Data Project Explorer 中 InfoSphere Warehouse Administration Console 用来管理 cube servers 及相应的立方体、导入元数据、优化多维分析查询。我们通过 Web 浏览器来访问 Administration Console。 使用 Administration Console,我们可以: 创建、删除、启动、停止、重启 cube server 增加、删除、启动、停止、重启立方体。我们也可以重建立方体成员缓冲或清空立方体的数据缓冲 导入元数据到 warehouse 元数据数据库中 运行 Optimization Advisor 创建并分析 MQT 使用情况 Cubing Services Optimization Advisor 通过基于多维模型、数据库统计信息、数据采样、磁盘空间及优化时间约束等因素对多维分析进行优化,提供创建汇总表(MQT)的功能,进一步提高多维查询的效率。 图 19. Optimization Advisor 多维模型优化的基本策略示意图 建立多维立方体模型 下面,我们通过 Infosphere Warehouse 提供的 Cubing Services 功能模块来建立多维分析模型。在 Infosphere Warehouse 中,多维数据模型由 Cube Model 及相应的 Cube 组成。 Cube Model 根据数据库底层的星型模型或雪花型模型为基础创建的,它包括 : Facts, 对应星型模型中的事实表 (Fact Table),它包含分析的量度(Measure)信息。度量数据通常分为可累加、半累加及不可累加三类,定义量度时应该指定其聚合方式。 Dimension,对应星型模型中的维表 (Dimension Table),Dimension 需要定义维的层次(Level),每一个维的层次都可以包含若干个属性 (Attribute) 信息,这些属性可以是层键值、描述信息(Descriptive)或相关信息(Relative)。同时,Dimension 还需要定义维的层次结构 (Hierarchy),它由若干个维的层次按上钻或下钻的顺序构成。 Join,定义事实及维之间连接关系。 Cube 是基于 Cube Model 创建的多维立方体。前端分析工具,如 Cognos,是针对特定 Cube 来进行多维分析的,它由 Cube Model 中的度量、维、维的层次结构组成。基于一个 Cube Model 可以创建多个 Cube。 图 20. Infosphere Warehouse OLAP 中的多维模型示意图 下面我们来设计一个“Purchase Profile Analysis”立方体模型。 首先,我们需要指定 Cubing Services 元数据数据库。在 Infosphere Warehouse 安装时,缺省会创建 DWECTRL 数据库,作为 Cubing Services 元数据数据库,我们也可以指定自己的数据库作为 Cubing Services 元数据数据库。我们在 Design Studio 中,选择窗口 -> 首选项 -> 数据仓储 -> 存储库,输入自己定义的数据库,如下图所示: 图 21. 指定 Cubing Services 元数据数据库 在 Design Studio 中,我们展开 DWEOLAP 数据设计项目下边的数据库模型,在 MARTS 模式下边的 OLAP 对象文件夹中,选择“立方体模型”条目,单击右键,选择“添加立方体模型 - 快速启动”启动“快速启动向导”,选择事实表 PRCHS_PRFL_ANLYSIS 来创建“Purchase Profile Analysis”立方体模型(Cube Model),如下图所示: 图 22. “Purchase Profile Analysis”立方体模型 在生成的“Purchase Profile Analysis”立方体模型中,我们要为量度定义聚合关系,为维度定义层及层次结构。 在 Cubing Services 中,我们支持如下类型聚合函数: AVG COUNT COUNT_BIG MAX MIN STDDEV SUM VARIANCE None 我们对 Cost Of Goods Sold (COGS),Number Of Items,Product Book Price Amount,Sales Amount 量度使用 Sum 聚集函数;对 Average Item Price Sold,Average Profit Amount Per Item,Profit Amount,Profit Margin Percentage 量度使用 none 聚集函数;对 Average Product Book Price 量度使用 AVG 聚集函数 在 Cubing Services 中,如下图所示,维度主要包含以下四种层次结构关系: 图 23. 维度四种层次结构关系 Balanced Hierarchy,平衡层次 Ragged Hierarchy,未对齐层次 Unbalanced Hierarchy,非平衡层次 Network Hierarchy,网络层次,每一个成员有不只一个父亲。 在生成的“Purchase Profile Analysis”立方体模型中,我们为: Product 维度定义了 Calendar Year Hierarchy查询路径,包括:Product Department Level, Product Sub Department Level, Product Class Level, Product Sub Class Level, Product Level; Store 维度定义了 Organization Unit Store Hierarchy查询路径,包括:Organization Unit Sub Division Level,Organization Unit Region Level,Organization Unit District Level,Organization Unit Store Level; Time 维度定义了两个查询路径: Calendar Year Hierarchy路径包括:Calendar Year Level,Calendar Year-Quarter Level,Calendar Year-Quarter-Month Level,Day of Calendar Month Level; Fiscal Year Hierarchy路径包括:Fiscal Year Level,Fiscal Year-Quarter Level,Fiscal Year-Quarter-Month; 在我们的实验中,所有层次结构都采用平衡层次方式。 当创建好“Purchase Profile Analysis”立方体模型后,我们通过选择“立方体”条目,点击右键,来创建“Price Analysis”立方体(Cube)。 在“Price Analysis”立方体中,我们使用“Purchase Profile Analysis”立方体模型中定义的“Cost Of Goods Sold (COGS),Number Of Items,Product Book Price Amount,Sales Amount,Average Item Price Sold,Average Profit Amount Per Item,Profit Amount,Profit Margin Percentage,Average Product Book Price 作为量度,使用 Product 维度及 Calendar Year Hierarchy 查询路径时间、Store 维度及 Organization Unit Store Hierarchy 查询路径产品、Time 维度及 Calendar Year Hierarchy 路径作为“Price Analysis”立方体中的维度。 验证及部署立方体模型 下面,我们要分析立方体模型的正确性,通过选择“Purchase Profile Analysis”立方体模型,点击右键,选择“分析模型“,进行立方体模型分析。 当验证立方体模型的正确性后,我们需要将“Purchase Profile Analysis”立方体模型部署到 DWEOLAP 数据库中 , 通过选择“Purchase Profile Analysis”立方体模型,点击右键,选择“部署到数据库“,进行立方体模型部署,如下图所示: 图 24. 立方体模型部署示意图 成功部署之后,在数据库资源管理器中可以看到已经部署到 DWEOLAP 数据库中的“Purchase Profile Analysis”模型。 我们可以在数据库资源管理器中,为多维模型进行优化,生成 MQT 表建议,通过选择“Purchase Profile Analysis”模型,点击右键,选择“优化顾问程序”来生成 MQT 表建议。如下图所示: 图 25. 多维模型优化示意图 在优化过程中,我们要选择合适的查询类型,我们选择了“向下钻取”查询类型,之后,系统自动生成 MQT 创建及数据刷新的脚本,如下边所示: createMQTS.sql 脚本内容:
refreshMQTs.sql 脚本内容:
运行上述 MQT 创建脚本,我们便在 DWEOLAP 数据库中创建了相应的 MQT 表来优化查询。 导入 OLAP 元数据并创建 Cubing Services Cube Server 接下来,我们需要导入 OLAP 元数据并创建 Cubing Services Cube Server。 管理 OLAP 元数据 保存在 InfoSphere Warehouse repository 中的多维模型元数据,需要通过数据源和保存在数据库中星型模型表进行关联。 在 administration console 中,我们通过选择 InfoSphere 仓库 -> 公共 -> 资源 -> 管理数据源,选择 Create 来创建 DWEOLAP 数据源。其中: JNDI Name选择 JDBC/cvsample;数据库名选择 DWEOLAP;数据库别名选择 DWEOLAP;主机名选择 localhost ;端口号选择 50000;数据库用户选择 db2admin;密码选择 db2admin 。 在 administration console 中,我们通过选择 InfoSphere 仓库 -> Cubing Services-> 管理 OLAP 元数据,选择已经部署的“Purchase Profile Analysis” 超链接,在立方体模型属性页中,选择“数据库映射”条目创建数据库资源映射 jdbc/dweolap。如下图所示: 图 26. 创建数据库资源映射示意图 创建 Cube Server 下边,我们来创建 Cube Server。在安装 InfoSphere Warehouse 后,我们需要至少创建一个 cube server 实例。创建 Cubing Services Cube Server,需要通过 administration console 来完成。 在 administration console 中,我们通过选择 InfoSphere 仓库 > Cubing Services > 管理立方体服务器,选择 Create 来创建 cube server 实例。如下图所示: 图 27. 创建 Cube Server 示意图 立方体服务器名称:我们输入 cubeserver1 主机名:输入 localhost 或 IP 地址 端口号:我们输入 8000 在 Cubing Services 中,主机名和端口号组合决定一个 Cube Server 实例,主机名和端口号组合在系统中必须唯一。Cube Server 需要使用连续 3 个端口,如果使用 HTTPS,需要使用连续 4 个端口。如上述例子,我们选择了 cube server 的端口号为 8000,这样,MDX 多维查询将使用端口 8000,8001 用于管理端口,缺省的 XMLA service over HTTP 使用端口 8002,Cognos 将使用该种接口访问 Cube Server, XMLA HTTPS 端口使用 8003。. 我们可以在创建完 Cube Server 后,改变 XMLA over HTTP 端口设置,请选择 InfoSphere 仓库 -> Cubing Services -> 管理立方体服务器,停止 cube server,点击 cubeserver1 超链接,在 cube server 属性页中,选择 XMLA tab,为 XMLA over HTTP 指定不同的端口号,之后点击 Save 保存我们的改变即可。 创建完 cubeserver1 立方体服务器后,选择“立方体”条目,选择添加” Price Analysis”立方体,并选择 InfoSphere 仓库 > Cubing Services > 管理立方体服务器,启动 cubeserver1 立方体服务器。 通过 Microsoft Excel 进行多维查询分析 当多维立方体创建好并部署到多维立方体服务器上之后,我们就可以通过 Microsoft Excel 采用 ODBO 的访问接口进行多维查询分析。 使用 Cubing Services ODBO provider,我们可以采用 Microsoft Excel 来读取 cube server 中的多维立方体中的数据。OLE DB for OLAP (ODBO) 是多维数据处理的业界标准。通过使用 Cubing Services ODBO provider, 它基于 OLE DB for OLAP 标准,我们可以访问 Cubing Services OLAP server 中的多维数据。 通过 ODBO , Microsoft Excel 可以以 PivotTable 或 PivotChart 方式显示 Cubing Services cube serve 中的多维立方体数据。目前,我们支持 Excel 2003 或 2007。 有关通过 Microsoft Excel 进行多维查询分析的具体方法,请参考 developerWorks 中国网站 Information Management 专区中“使用 Excel 分析 InfoSphere Warehouse 多维数据”一文。 通过 Cognos 8.4 进行多维查询分析 Cognos 8 采用基于 SOA 架构,允许不同组件运行在统一的应用架构中。如下图所示: 图 34. Cognos 8 体系结构 用户通过 IBMCognos Connection 默认的门户,采用浏览器方式创建报表及访问从中央内容存储库中发布的内容信息。用户还可以通过 IBMCognos Connection 默认的门户管理、配置 Cognos 8 服务器属性。IBM Cognos Framework 是一个建模及开发工具,用于生成用户端报表所需要的元数据模型。它是一个客户端程序。发布包或查询信息,都要通过 IBM Cognos 8 server。 从 Infosphere Warehouse 9.5.2 开始,对于 Cognos 8.4 版本及更高版本,可以支持直接连接 Cubing Services,也就是说,用于发布包(package )的元数据可以直接从 Cube Server 中得到,而不再需要将所有的多维模型元数据导入到 Framework Manager 中。我们仍然需要通过 Framework Manager 发布包来访问 Cube Server 中的立方体,但我们不需要对 Cube Server 中的立方体做任何改变。 要连接 Cubing Services,我们需要在 Cognos 8.4 中定义一个数据源来连接 Cube Server,并将立方体导入到 Framework Manager 中。在 Framework Manager 中导入的立方体仅仅是一个 stub 对象,用来引用 Cubing Services Cube Server 中的立方体;关于立方体的元数据,包括维、维层次、维层次结构信息,仍然保存在 Cubing Services 中。 采用 Cognos 8.4 访问 InfoSphere Warehouse 9.5.2 配置的基本步骤包括: 安装 Cognos BI server 8.4 及 Cognos BI model 8.4 创建并配置 DB2 数据库用于 Cognos 8.4 内容库 配置 IBM HTTP server 用于 Cognos 的 web 服务器 通过 Cognos configuration tool 配置内容库 测试内容库连接并启动 Cognos 服务 通过 framework manager 创建 cube 模型 创建 Cognos 包并发布包 采用 Report Studio 创建报表 下边我们具体介绍一下配置步骤: 创建并配置 DB2 数据库 我们本次实验,将采用 DB2 数据库作为 Cognos 内容库,我们创建 content 作为 cognos 内容库。创建 cognos 内容库时,需要创建 UTF-8 数据库,同时,cognos 要求创建一个 32K 页面的缓冲池及 4K 页面大小的缓冲池;创建 32K 页面大小的系统临时表空间;创建 4K 页面大小的用户临时表空间;创建 4K 页面大小的 regular 用户表空间。需要调整 db cfg 中的 Application heap size (applheapsz) 参数为 1024 KB,Lock timeout (locktimeout) 参数为 240 seconds。 我们可以采用下面脚本来创建数据库并进行相应的配置:
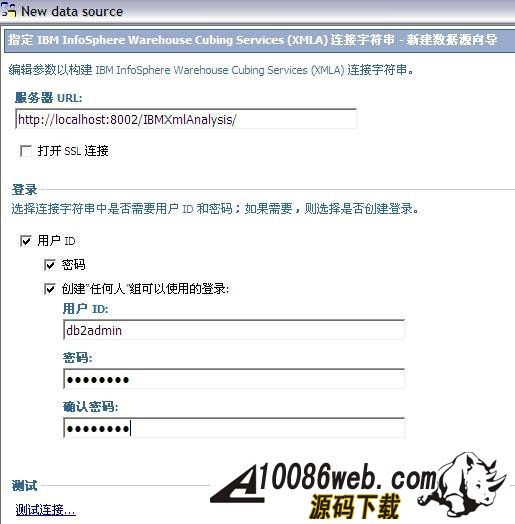
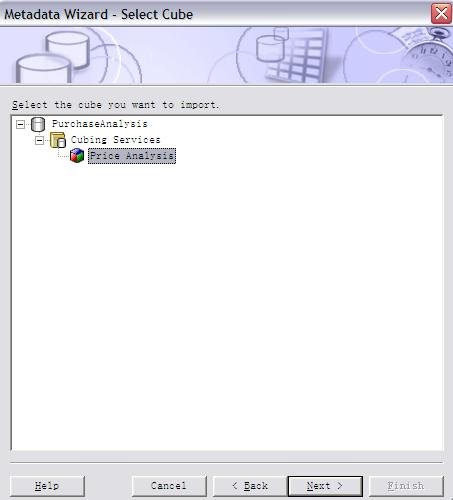
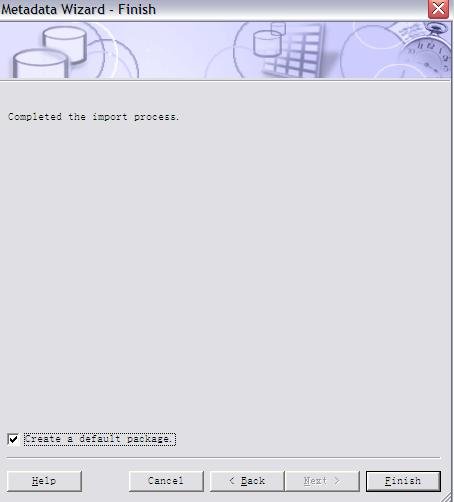
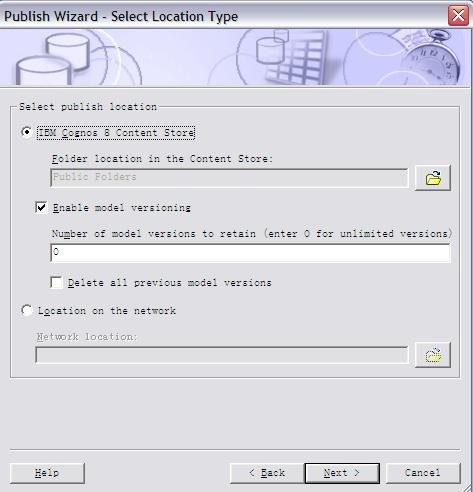
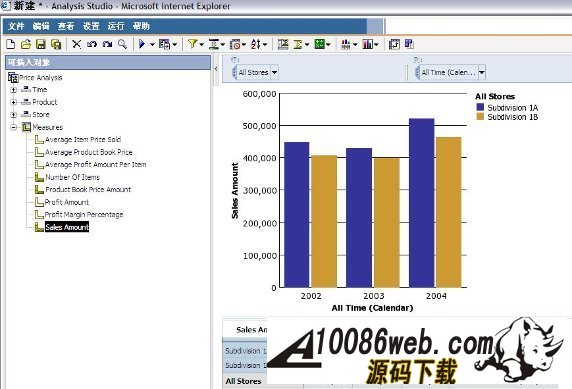
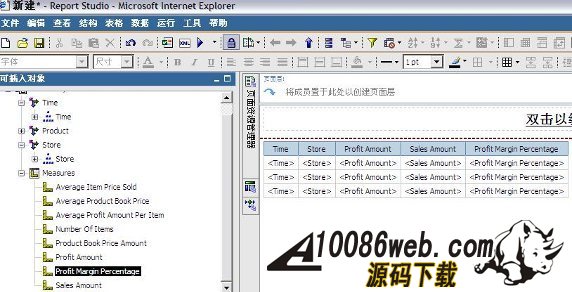
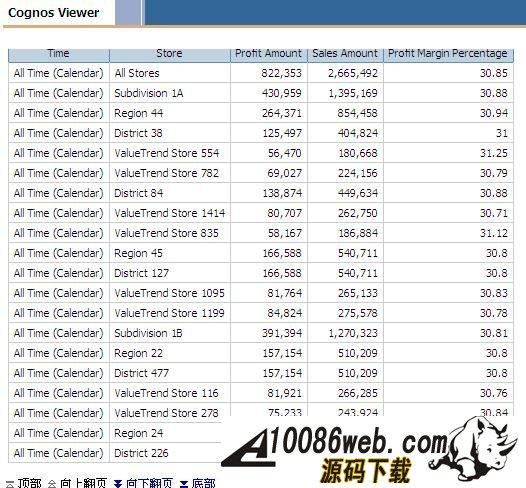
同时,我们还需要将 DB2 jar files (db2jcc.jar, db2java.zip, and db2jcc_license_cu.jar) 从 c:\program files\IBM\SQLLIB\java 目录拷贝到 c:\program files\cognos\c8\webapps\p2pd\web-inf\lib 目录下;并将 c:\program files\cognos\c8\webapps\p2pd\web-inf\lib 目录下 db2java.zip 文件改为 db2java.jar。 配置 IBM HTTP server 用于 Cognos 的 web 服务器 当安装完 IBM HTTP Server 后,我们可以在浏览器中输入 /uploadfile/201212/2/CA161358225.jpg" /> 测试内容库连接并启动 Cognos 服务 我们选择本地配置 -> 数据访问 ->content Manager, 选择 cognos,点击右键,选择“测试”进行连接测试;当测试成功后,我们选择“操作”菜单项 ->“启动”,或者在工具栏中点击 “启动按钮”启动 cognos 服务。当 cognos 服务启动完成后,我们就可以在浏览器中输入 /uploadfile/201212/2/DC161358383.jpg" /> 在创建 project 时,系统提示选择语言,默认为中文。之后,出现 Metadata Wizard-Select Metadata Source 窗口,我们选择 data source, 下一步出现,Metadata Wizard-Select Data Source 窗口,我们选择 new创建新的数据源,此时,出现 New Data Source 窗口,点击下一步,在名称栏目,输入 PurchaseAnalysis作为新的数据源名称,点击下一步,出现下图所示窗口: 图 37. 选择 IBM InfoSphere Warehouse Cubing Services(XMLA) 在类型栏目,选择 IBM InfoSphere Warehouse Cubing Services(XMLA),点击下一步,出现下图所示窗口: 图 38. 设置 Cube Server 连接属性 在服务器 URL栏目:输入 http://localhost:8002/IBMXmlAnalysis/,选择用户 ID,密码检查框,在用户 ID栏目:输入 db2admin,在密码栏目:输入 db2admin,之后,选择测试连接…测试是否可以连接到 Cubing Services Cube Server。系统将出现如下窗口: 图 39. 测试 Cube Server 连通性 选择测试,测试成功后,选择完成,这样,我们就创建了 PurchaseAnalysis 数据源。 之后,系统出现 Metadata Wizard-Select Data Source 窗口,我们选择刚创建好的 PurchaseAnalysis 数据源,点击下一步,此时,系统出现下图所示窗口: 图 40. 选择 Price Analysis 立方体 系统显示出我们在 Cubing Services Cube Server 中所定义的 Price Analysis 立方体,选择 Price Analysis 立方体,点击下一步,此时,系统出现下图所示窗口: 图 41. 完成了元数据导入工作 到此,我们在 Framework manager 中完成了元数据导入工作。下边,就可以进行创建及发布包的工作了。 如果我们选择了 create a default package 选项,系统会自动调用创建及发布包的操作。 创建 Cognos 包并发布包 当我们点击 finish后,系统会自动调用创建及发布包的操作。此时,系统会出现创建包窗口,在包名称栏目:我们输入 Price Analysis, 系统会自动生成 Price Analysis 包,之后,系统提示,是否需要打开 publish package wizard。选择 yes后,系统出现下图所示窗口: 图 42. 创建 Price Analysis 包 点击下一步,选择 No Security Defined,继续点击下一步,系统出现下图所示窗口: 图 43. 发布 Price Analysis 包 点击 publish,完成了 Price Analysis 包发布工作。这时,我们就可以使用 report studio、analysis studio 等工具来进行查询分析了。 采用 Report Studio、Analysis Studio 等工具来进行查询分析 我们可以在浏览器中输入 /uploadfile/201212/2/B116140969.jpg" /> 采用 analysis studio 来进行多维分析 我们首先采用 analysis studio 来进行多维分析。我们选择分析我的业务,系统出现下图所示窗口,我们选择 Price Analysis 数据包, 图 45. 选择 Price Analysis 数据包 之后,我们选择空白分析,点击确定。 图 46. 选择空白分析 我们就可以进行多维分析了,如下图所示: 图 47. analysis studio 多维分析结果示意图 采用 report studio 来创建报表 接下来,我们采用 report studio 来创建报表。我们选择创建专业报表,同样,我们选择 Price Analysis 数据包,之后,选择列表报表类型,如下图所示: 图 48. 选择创建报表类型 之后,创建如下所示报表: 图 49. report studio 创建报表示意图
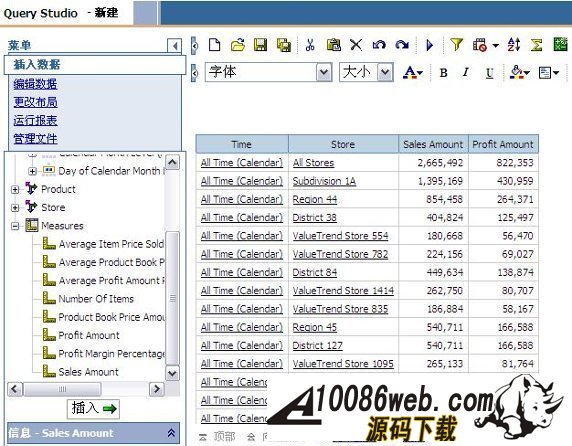
采用 query studio 来创建查询 接下来,我们采用 query studio 来创建查询。我们选择查询我的数据,同样,我们选择 Price Analysis 数据包 , 进行如下查询: 图 51. query studio 查询结果示意图 结论 通过上述的几个部分工作,我们实现了一个最基本的数据查询分析应用,通过它,我们可以基本了解使用 InfoSphere Warehouse 及 Cognos 来快速开发数据查询分析应用的基本方法及步骤,为进一步开发更复杂的数据分析应用打下坚实的基础。 (责任编辑:admin) |