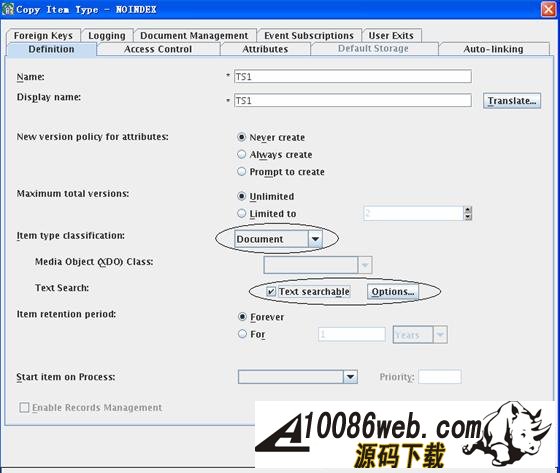
简介 Text Search 是 IBM 内容管理产品(CM, Content Manager)的一个重要的功能。本文首先简要介绍了基于 Oracle 数据库的 CM Text Search 的概念,并对其功能做了简要的描述,从而引出 Oracle Text 的处理方法及实现流程,在此基础上介绍了 CM 在基于 Oracle Text 技术之上的 Text Search 功能的具体实现。在此之后,提供了扩展 CM Text Search 功能的具体实现方法,并介绍了如何通过监控维护 Text Index,保证 Text Search 结果的准确性及提高 Text Search 的性能。 CM 中的 Text Search CM 管理各种类型的文档,例如 pdf,word 等。对这些文档内容的文本检索,是 CM 很重要的一个功能部分。 CM 的 Text Search 对存储在 CM 中的文本可检索 (text searchable) 文档建立基于文档信息的索引,便于对我们所需要的文档的检索,使用和管理。 那么如何触发 CM Text Search 的功能呢?在 CM 中,在我们定义数据模型(DATA MODEL)的时候是可以配置到底哪些文档是需要 Text Search 功能的。如图 2-1 所示,当我们在 System Administration Client 中定义一个 TS1 的 ITEM TYPE 时,如果我们选择“ Item Type Classification ”的值为 Document, 那么在” Text Search ”的部分就可以去选择 Text Searchable 。 图 1. 配置 Text Searchable Item Type
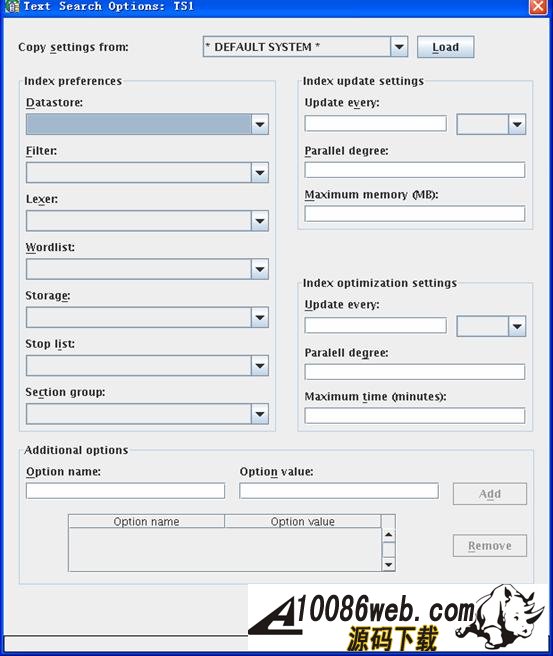
图片看不清楚?请点击这里查看原图(大图)。 这个时候点击 options 按钮就可以得到展开的界面如图 2 所示。在这个界面上,可以选择适合的 Text Index 参数去创建 Text Index 。 图 2. Text Index 参数定义
图片看不清楚?请点击这里查看原图(大图)。 Oracle Text 的处理方法及实现流程 在上面一节,我们看到了定义 Text Search 选项的界面,这个界面各个输入项的具体含义是什么,我们需要从 Oracle Text 的方面去说明。 在 Oracle Text 中,为了建立 Text Index,需要解决如下几个问题: 文档是如何存储的? 文档怎样才能转换成文本格式 (plainText) 的文件 用什么语言规则进行索引? 词根和模糊查询应该怎样展开进行? 索引数据怎样存储? 哪些词句和主题不需要索引? 怎么定义区域? 对于上述各个问题,在图 2 中有对应的各个输入参数框给予了相应的回答。下面的表格给出了上述问题和 CM Text Index 属性之间的对应关系。 表 1. 参数对应关系表
这样的话,Oracle Text 就会根据用户的输入参数生成对应的 Text Index 。其对 Text Index 的生成过程,就是对于用户输入参数的处理过程。这个过程如图 3 所示: 图 3. Oracle Text Index 处理流程
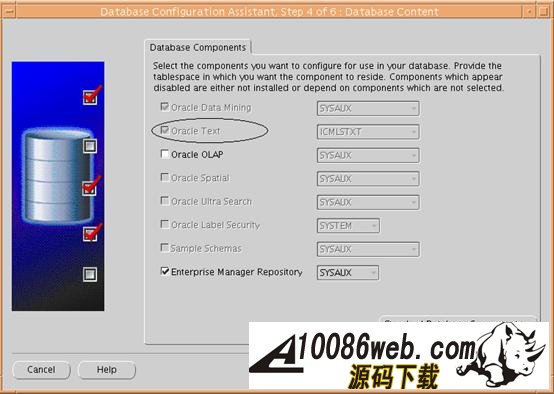
在这个处理过程中,Datastore 描述了文档从何处 ( 文件系统,internet 或者 数据库表等地方 ) 取得,取得文档后,根据 Filter 定义的信息或方法把文档转换成余下过程可以识别的文本信息,Sectioner 根据 Section Group 给定的定义标志出区域信息送给索引引擎(Indexing Engine),并把文本信息继续传送给 Lexer,Lexer 根据对应参数的规范把文本信息处理成一个个索引标志送给索引引擎,索引引擎根据 Wordlist 给出对应的词根及模糊查询的文本段,以及除掉 stoplist 中列出的不需要索引的标志信息。并结合 Storage 信息把得到的 Text Index 存储在数据库中。 Text Search 功能的配置 如果我们需要基于 ORACLE 数据库的 CM 的 Text Search 功能,需要在配置 CM 的过程中进行如下操作: A. 在用 DBCA 配置 CM Library Server 需要的数据库时,需要配置上 Oracle Text 属性,即勾上 Oracle Text 选项。如图 4 所示: 图 4. DBCA 配置 Oracle Text 属性窗口
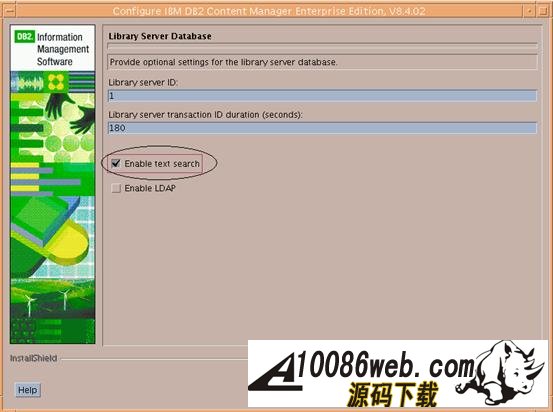
图片看不清楚?请点击这里查看原图(大图)。 B. 在配置 Library Server 时,需要在如图 5 的界面中选择 Enable text search. 图 5. CM configuration 的 Enable Text search 属性窗口
图片看不清楚?请点击这里查看原图(大图)。 如果一个已存在的 CM 系统中没有配置 Text Search 属性,那么我们是否可以对其进行配置呢,答案是肯定的。其配置方法如下: 1. 首先通过 DBCA 对已有 Library Server 数据库配置 Oracle Text 功能,其界面同图 4 ; 2. 用 sqlplus 运行脚本 $IBMCMROOT/config/icmlsoratxt.sql(命令如下),配置 CM Text Search
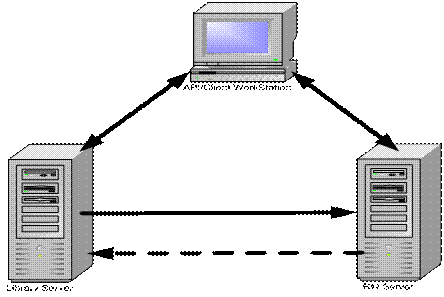
CM 的 Text Search 功能的内部实现 CM 总体上来讲是一个三角形架构,如图 6 所示 , 其由 Library Server, RM(Resource Manager) 和通过 API 开发的客户端组成。 图 6. CM 的三角架构图
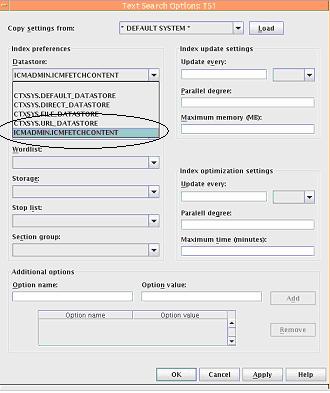
在通常情况下,CM 的文档是存储在 RM 中,而描述文档的元数据及 Text Index 信息是存储在 Library Server 中。所以在建立和更新 Text Index 数据的过程中就需要一个存储过程 (store procedure) 从 RM 中提取文档。 CM 中定义了一个名为 ICMFETCHCONTENT 的存储过程去 RM 中提取文档。在建立 Data Model 时,就可以选择这个方法作为 Datastore 的输入值去配置 Text Search 的属性,如图 7 所示。 图 7. Text Index 的属性定义窗口
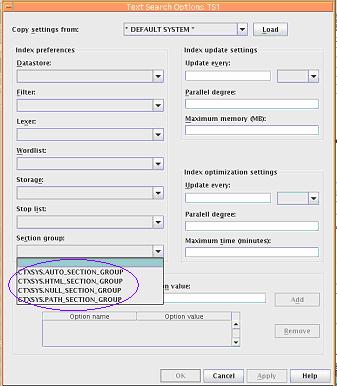
需要注意的是:只有配置了 CM Text Search 功能,才能配置 ICMFETCHCONTENT 方法作为 datastore 参数的输入值,如何配置 CM Text Search 详见下一节。 如何扩展 CM TEXT SEARCH 的功能 在图 7 中,我们可以看到在每个下拉输入框的可选参数是固定的,而且都只有一些最基本的选项可供选择。可以看到,在所有界面上的 Index preferences 选项中,除了 datastore 中的 ICMFETCHCONTENT 是 CM 定义的,其他的都是 Oracle Text 本身预定义的。这些 Oracle Text 预定义的参数在通常情况下可以满足客户的需求。然而,对于一些用户来说,如果现有的参数不能满足他们特有的需求,在 CM 中可以增加一些用户定制的 Index preferences 去满足这些需求。这样的话,在图 7 中就可以选择这些新定义的选项作为 Item Type 的 Text Index 属性的一部分。 在这里,我们以自定义 section group 的选项为例来看看如何为 Index preferences 添加新的属性选项。如图 8 所示,在默认的情况下,可以看到在的 section group 选项只有 4 个。 图 8. Text Index 的属性定义窗口
我们可以用下列过程去定制一个新 Section Group: a. sqlplus 中用 Library Server 中的 schema user ID 登录 Library Server 的数据库; 例如 : sqlplus / nolog
b. 运行如下语句:
结果如下图 9 所示。 图 9. Section Group 的定义方法
图片看不清楚?请点击这里查看原图(大图)。 如图 10 所示,定义完这个新的 ICMADMIN.HTMGROUP 选项后,再打开 Text Search Options 属性窗口就可以从 Section Group 选项列表看到它了。 图 10. Text Index 属性窗口(HTMGROUP 可供选择)
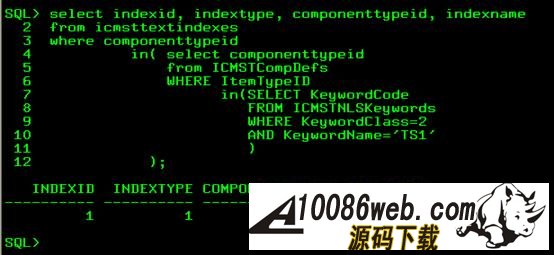
通过如上实例,用户就可以使用新的基于段内的查询语句查询所需文档。同理,其他的 Index preferences 参数选项也可以使用 Oracle Text 提供的方法加以增加,用户通过这些自定制的 Text Index 属性,可以丰富查询信息的方式,使查询更加符合自己的习惯与需要,从而实现对查询方式及文档格式支持的多样化。 监控维护 Text Index 在定义一个具有文本可检索 (Text Searchable) 的 Item Type 时,如图 10 所示,“ Index optimization setting ”跟” Index update setting “并不是必须有输入值的属性。如果没有定义” Index update setting ”,当我们新增加一些文档后,用 Text Search 去试图查询这些文档时就会发现,原本应该在结果集中的这些新增文档并没有出现。原因就在于在 CM 中使用了 CONTEXT 类型的 Text Index,而这种类型的文本索引 (Text Index) 数据并不是自动随文档数据的更新而更新的。如果碰到这种情况,需要用如下步骤去更新文本索引(以 Item Type 的名称为 TS1 为例): a) 用如下语句去找到对应 Item Type 的 Text Index:
其结果如图11,TS1 的 Text Index 的名称为 ICMUU01008001TIE 。 图 11. 索引名称查询结果
图片看不清楚?请点击这里查看原图(大图)。 b) 通过 Text Index 的名称去更新 Index 的数据。其语句如下:
其运行结果如图12所示。 图 12. 同步更新方法
图片看不清楚?请点击这里查看原图(大图)。 如果没有定义“ Index optimization setting ”区域,当频繁的进行插入删除更新文档时,将会导致查询速度变慢,此时,可以用下述方法对对应的索引进行优化处理以提高查询性能,过程如下: a. 用上述语句 ( 图 11 所示 ) 找到 Item Type 对应的 Text Index 的名称; b. 运行如下语句进行对应 Index 的优化:
其运行结果如图 13 所示。 图 13. 优化 Index 方法
图片看不清楚?请点击这里查看原图(大图)。 下面我们来介绍一下如何去查看 Text Index 一些相关信息,这些查询信息可以帮助我们去监控 Text index 的状态,提醒我们可能需要做的一些优化,首先我们可以用运行如下语句去获得 Tex index 的一些信息:
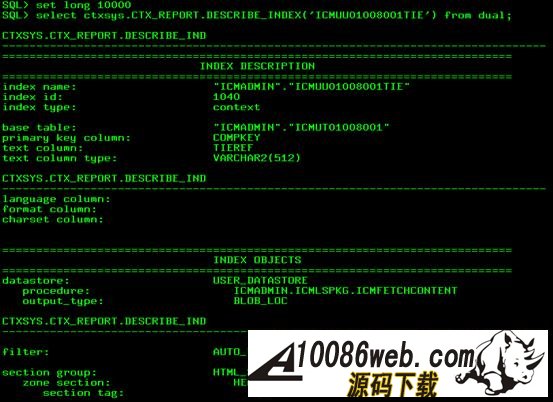
可以看到的结果是如图14所示。 图 14. Index 信息查看方法
图片看不清楚?请点击这里查看原图(大图)。 在上图中,我们可以看到 Text Index 的 Index 类型,数据存储方式,已经其他定义信息,包括索引数据的存储方法,如果我们从这些信息中发现其定义的方式不符合我们的要求,如索引数据的表空间不符合查询优化的方式或表空间本身的存储空间不符合我们的要求,我们可以更改这些参数从新定义我们的 Text Index 。 我们也可以通过 CTX_REPORT.INDEX_STATS 去监控 Text Index 因频繁增删改而产生的碎片(fragmentation), 如果其已经影响到了我们的查询效率,我们可以用图 13 所示方法进行优化,清除碎片。 总结 通过本文的介绍,相信您会对 Oracle Text 的基本配置,CM Text Search 的作用,功能配置,实现,扩展以及 Text Index 监控维护这几个方面有了一定的了解和学习,您可以在 CM 系统中根据自己的需要定制和管理自己的 Text Index 属性,从而能更加有效地使用文本检索并管理自己的文档。 (责任编辑:admin) |