OSPF连载:OSPF划分区域详解

我们在讲述OSPF协议特点之初提到过OSPF可以支持大规模网络。如果规划合理1000多台路由器也是没有问题的。然而支持大规模网络是一件非常复杂的事情。虽然从理论上建立了一套可行的方法,但在实际中网络会经常发生变化。这种变化随着网络中的设备越多,变化的机率就越大。有些问题就会由量变导致质变,这就是说有些协议在理论上是可行的,但实际组网中已经到了协议不能应用的状态。接下来我们来看如果大规模网络中使用OSPF协议可能存在的一些问题。
首先,在大规模的网络中存在数量众多的路由器,会生成很多LSA,整个LSDB会非常大,甚至占用2-3M的内存容量。这当然跟路由算法有关,因为链路状态算法本省就存储了很多信息。比如RIP协议在发送信息的时候只发送路由信息,而OSPF算法不仅发送路由信息还要发送链路状态。
其次,OSPF算法会增加耗时,造成CPU负担增大。第一、OSPF携带信息较多,通过SPF算法得出树状结构。第二、当网络中存在众多运行OSPF路由协议的设备则会生成很多LSA。当一台设备出现变化时,整个网络随之变化。这在一些大型的网络中造成的灾难是无法想象的。
那么如果解决这些问题呢?通常我们解决问题的方法就是分区域,缩小问题范围。事实上,OSPF协议也是如此。OSPF将一个自制系统分成若干个区域,采用分级管理,这就缩小了网络。
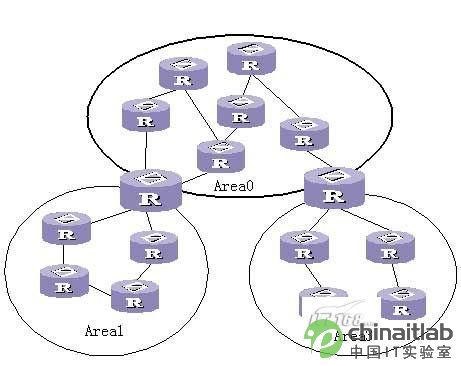
不同的是,区域通过一个32位的整数来标示,叫做Area ID。有些类似我们前面讲到过的Router ID,Area ID是用来区别区域的, Router ID是用来区分路由器的。然后既然产生了区域,那么势必会产生区域的边界,区域的边界有两种划分,一种是用一台路由器来当作区域的边界,另一种是把网段当作区域的边界,比如BGP。在OSPF划分区域时是采用路由器当作区域的边界。