1. 数据库的数据存储
1.1文件:
我们一旦创建一个数据库,都会生成两个文件:
DataBaseName.mdf: 主文件,这是数据库中的数据最终存放的地方。
DataBaseName.ldf:日志文件,由数据操作产生的一系列日志记录。
1.2分区:
在一个给定的文件中,为表和索引分配空间的基本存储单位。 1个区占64KB,由8个连续的页组成。 如果一个分区已满,但需存一条新的记录,那么该记录将占用整个新分区的空间。
1.3 页:
分区中的一个分配单位。这是实际数据行最终存放的地方。 页用于存储数据行。
Sql Server有多种类型的页:
Data, Index,BLOB,GAM(Global Allocation Map),SGAM,PFS(Page Free Space),IAM(Index Allocation Map),BCM(Bulk Changed Map)等。
2. 索引
2.1.1索引
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度。索引包含由表或视图中的一列或多列生成的键。这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关联的行。
通俗点说,索引与表或视图相关,旨在加快检索速度。索引本身占据存储空间,通过索引,数据便会以B树形式存储。因此也加快了查询速度。
2.1.2聚集索引
聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。索引定义中包含聚集索引列。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序排序。只有当表包含聚集索引时,表中的数据行才按排序顺序存储。如果表具有聚集索引,则该表称为聚集表。如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
通俗点说,聚集索引的页存储的是实际数据。每个表只能建立唯一的聚集索引,但也可以没有。
如果建立聚集索引,那么表中数据以B树形式存储数据。
对于聚集索引的理解,打个比方,即英文字典的单词编排。 英文字典单词以A,B,C,D….X,Y,Z的形式顺序编排,如果我们查找 Good 单词,我们首先定位到G,然后定位o – o-d. 最终查找到Good,便是good实际存在的地方。
建聚集索引需要至少相当该表120%的附加空间,以存放该表的副本和索引中间页。
2.1.3非聚集索引
非聚集索引具有独立于数据行的结构。非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
从非聚集索引中的索引行指向数据行的指针称为行定位器。行定位器的结构取决于数据页是存储在堆中还是聚集表中。对于堆,行定位器是指向行的指针。对于聚集表,行定位器是聚集索引键。
通俗点说,非聚集索引的页存储的是不是实际数据,而是实际数据的地址。一个表可以存在多个非聚集索引。在Sql Server2005中,每个表最多可以建立249个,而在Sql server2008中,则最多可以建立999个非聚集索引。
对于非聚集索引的理解,即新华字典的“偏旁部首”查字法。遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
2.1.4 覆盖索引:
覆盖索引是指那些索引项中包含查寻所需要的全部信息的非聚集索引,这种索引之所以比较快也正是因为索引页中包含了查寻所必须的数据,不需去访问数据页。 如果非聚簇索引中包含结果数据,那么它的查询速度将快于聚集索引。
但是由于覆盖索引的索引项比较多,要占用比较大的空间。而且update 操作会引起索引值改变。所以如果潜在的覆盖查询并不常用或不太关键,则覆盖索引的增加反而会降低性能。
2.1.5 主键和索引
主键:表通常具有包含唯一标识表中每一行的值的一列或一组列。这样的一列或多列称为表的主键 (PK),用于强制表的实体完整性。在创建或修改表时,您可以通过定义 PRIMARY KEY 约束来创建主键。 它是一种唯一索引。
下面是一个简单的比较表
| 主键 | 聚集索引 |
用途 | 强制表的实体完整性 | 对数据行的排序,方便查询用 |
一个表多少个 | 一个表最多一个主键 | 一个表最多一个聚集索引 |
是否允许多个字段来定义 | 一个主键可以多个字段来定义 | 一个索引可以多个字段来定义 |
|
|
|
是否允许 null 数据行出现 | 如果要创建的数据列中数据存在null,无法建立主键。 | 没有限制建立聚集索引的列一定必须 not null . |
是否要求数据必须唯一 | 要求数据必须唯一 | 数据即可以唯一,也可以不唯一。看你定义这个索引的 UNIQUE 设置。 |
|
|
|
创建的逻辑 | 数据库在创建主键同时,会自动建立一个唯一索引。 | 如果未使用 UNIQUE 属性创建聚集索引,数据库引擎 将向表自动添加一个四字节 uniqueifier 列。 |
2.2 索引的存储结构
2.1.1 整表扫描和索引扫描
整表扫描和索引扫描是Sql Server数据库检索到数据的唯一的两种方式。除此之外,没有第三种方式供Sql Server检索到数据。
整表扫描
最直接的检索方式, Sql Server进行表扫描时,会从表头开始扫描,直到整个表结束。 当找到符合条件的记录,便把该记录存在结果集中。对于小数据量的表,这是一种很快捷的方式。如果没有为表创建索引,那么Sql server便按这种方式检索数据。
索引扫描
如果为表创建了索引,在进行检索前,Sql Server优化器会根据查询条件,从可用的索引中选择最优化的索引。检索时,便会遍历B树,当找到符合条件的记录,便把该记录存在结果集中。因此,检索大数据量的表,使用索引相对于整表扫描会显著地提高性能。
2.1.2 B-Tree
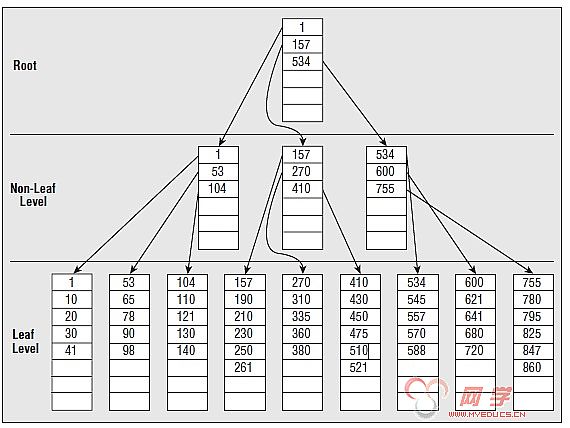
2.2.3 聚集索引
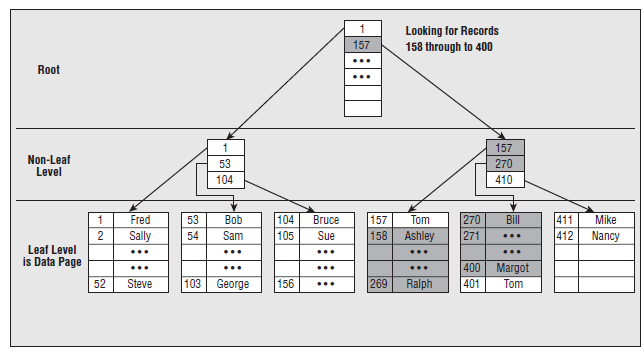
叶子节点存放的是实际的数据。索引的入口点存放在master->sys.indexes中。
2.2.4 非聚集索引
2.4.1 堆上的非聚集索引(Non-clustered index on heap)
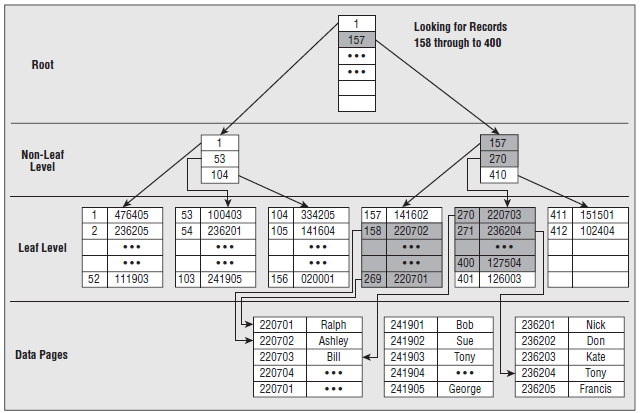
与聚集索引很类似。
不同处在:
叶子节点存放的不是实际数据,而是指向实际数据的指针。检索速度非常接近于聚集索引,比起聚集索引,实际上只是多一步由根据指针检索到实际数据的过程。
2.4.2 聚集表上的非聚集索引
3. 管理索引
3.1 创建
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX <index name> ON <table or view name>(<column name> [ASC|DESC] [,n])
INCLUDE (<column name> [, n])
[WITH
[PAD_INDEX = { ON | OFF }]
[[,] FILLFACTOR = <fillfactor>]
[[,] IGNORE_DUP_KEY = { ON | OFF }]
[[,] DROP_EXISTING = { ON | OFF }]
[[,] STATISTICS_NORECOMPUTE = { ON | OFF }]
[[,] SORT_IN_TEMPDB = { ON | OFF }]
[[,] ONLINE = { ON | OFF }
[[,] ALLOW_ROW_LOCKS = { ON | OFF }
[[,] ALLOW_PAGE_LOCKS = { ON | OFF }
[[,] MAXDOP = <maximum degree of parallelism>
]
[ON {<filegroup> | <partition scheme name> | DEFAULT }]
3.2 修改
ALTER INDEX { <name of index> | ALL }
ON <table or view name>
{ REBUILD
[ [ WITH (
[ PAD_INDEX = { ON | OFF } ]
| [[,] FILLFACTOR = <fillfactor>
| [[,] SORT_IN_TEMPDB = { ON | OFF } ]
| [[,] IGNORE_DUP_KEY = { ON | OFF } ]
| [[,] STATISTICS_NORECOMPUTE = { ON | OFF } ]
| [[,] ONLINE = { ON | OFF } ]
| [[,] ALLOW_ROW_LOCKS = { ON | OFF } ]
| [[,] ALLOW_PAGE_LOCKS = { ON | OFF } ]
| [[,] MAXDOP = <max degree of parallelism>
) ]
| [ PARTITION = <partition number>
[ WITH ( <partition rebuild index option>
[ ,n ] ) ] ] ]
| DISABLE
| REORGANIZE
[ PARTITION = <partition number> ]
[ WITH ( LOB_COMPACTION = { ON | OFF } ) ]
| SET ([ ALLOW_ROW_LOCKS= { ON | OFF } ]
| [[,] ALLOW_PAGE_LOCKS = { ON | OFF } ]
| [[,] IGNORE_DUP_KEY = { ON | OFF } ]
| [[,] STATISTICS_NORECOMPUTE = { ON | OFF } ]
)
} [ ; ]
3.3 删除
DROP INDEX <table name>.<index name>
4. 使用索引应注意十么
1)聚集索引通常速度优于非聚集索引
2) 建索引时应考虑是否有足够的空间。索引占据空间,平均约1.2倍数据库本身大小。
3) 在经常用于查询或聚合条件的字段上建立聚集索引。这类查询条件包括 between, >, <,group by, max,min, count等。
4) 不要在经常作为插入,且插入字段无序的列上建立聚集索引。 插入数据行会涉及分页,rebuild索引会消耗大量时间。参考文末"一个不恰当使用聚集索引的例子"。
5) 在值高度的唯一性字段上建立索引。不能在诸如性别的字段上建立索引。
6) 只有作为索引的第一个列包含在查询条件中,该索引才的作用。
打个比方,我们用偏旁+部首来查汉字,那么偏旁首先必须包括在查询条件中,只有先定位偏旁,再结合部首,才能发挥偏旁+部首来检索的快速功效。
7) 删除一直不用的索引。特别是对于删除和修改比较频繁的数据表,必须考虑如何精华索引。
一个不恰当使用聚集索引的例子(摘自"Microsoft Sql Server 2008 Programming" Chapter 6, Rob Vieira):
Imagine this scenario: You are creating an accounting system. You would like to make use of the concept
of a transaction number for your primary key in your transaction files, but you would also like those
transaction numbers to be somewhat indicative of what kind of transaction it is. (It really helps troubleshooting
by your accountants.) So, you come up with something of a scheme: You’ll place a prefix on
all the transactions indicating what sub-system they come out of. They will look something like this:
ARXXXXXX Accounts Receivable Transactions
GLXXXXXX General Ledger Transactions
APXXXXXX Accounts Payable Transactions
where XXXXXX will be a sequential numeric value.
This seems like a great idea, so you implement it, leaving the default of the clustered index going on the
primary key.
At first look, everything about this setup looks fine. You’re going to have unique values, and the accountants
will love the fact that they can infer where something came from based on the transaction number.
The clustered index seems to make sense since they will often be querying for ranges of transaction IDs.
Ah, if only it were that simple. Think about your inserts for a bit. With a clustered index, you originally
had a nice mechanism to avoid much of the overhead of page splits. When a new record was inserted
that was to go after the last record in the table, then, even if there was a page split, only that record would
go to the new page, SQL Server wouldn’t try to move around any of the old data. Now you’ve messed
things up though.
New records inserted from the General Ledger will wind up going on the end of the file just fine. (GL
is last alphabetically, and the numbers will be sequential.) The AR and AP transactions have a major
problem though; they are going to be doing non-sequential inserts. When AP000025 gets inserted and
there isn’t room on the page, SQL Server is going to see AR000001 in the table, and know that it’s not
a sequential insert. Half the records from the old page will be copied to a new page before AP000025 is
inserted.
The overhead of this can be staggering. Remember that you’re dealing with a clustered index, and that
the clustered index is the data. The data is in index order. This means that, when you move the index
to a new page, you are also moving the data. Now imagine that you’re running this accounting system
in a typical OLTP environment (you don’t get much more OLTP-like than an accounting system) with a
bunch of data-entry people keying in vendor invoices or customer orders as fast as they can. You’re going
to have page splits occurring constantly, and every time you do, you’re going to see a brief hesitation for
users of that table while the system moves data around.
Fortunately, there are a couple of ways to avoid this scenario:
? Choose a cluster key that is going to be sequential in its inserting. You can either create an identity
column for this or you may have another column that logically is sequential to any transaction
entered regardless of system.
? Choose not to use a clustered index on this table. This is often the best option in a situation like
that in this example, since an insert into a non-clustered index on a heap is usually faster than
one on a cluster key.
