SQL Server2005РЉеЙКЏЪ§вбОВЛЪЧвЛМўЪВУДаТЯЪЕФЪТСЫЃЌЕЋЪЧЮвПДЭјЩЯЕФДѓВПЗжЖМЪЧЫЕОлКЯКЏЪ§ЃЌР§згвВБШНЯЧГЃЌФЧУДетРяОЭНВНВЮвдЫгУРЉеЙКЏЪ§РДгХЛЏЪ§ОнПтадФмЕФР§згЃЌЯЃЭћКЭДѓМввЛЦ№ЗжЯэетИіОбщЁЃ
ашЧѓЫЕУї
ДѓМвдкЪЙгУSQL ServerПЊЗЂЕФЪБКђвЛЖЈЛсгіЕНетбљЕФашЧѓЃЌФЧОЭЪЧЭЈЙ§Table_Name1БэЕФСНИізжЖЮColumn1ЁЂColumn2РДВщбЏдкTable_Name2БэжаЗћКЯетСНИіЬѕМўЕФМЧТМЃЌВЂЗЕЛиTable_Name2жаЕФзжЖЮColumn3ЃЌУцЖдетбљЕФашЧѓЃЌФувВаэЛсЫЕЪЙгУБэСЌНгОЭПЩвдСЫЃЌЖдЕФЃЌУЛДэЃЌЮввВЪЧетбљЯыЕФЃЌЕЋЪЧгаЕФЪБКђЭљЭљвЊУцЖдВЛЭЌЕФЭЛЗЂЧщПіЃЌФЧОЭЪЧВЂВЛЪЧвЛЖЈЛсColumn1гыColumn2ЪЧШЋЦЅХфЕФВщбЏЃЌПЩФмжаМфЛЙашвЊвЛаЉТпМЕФДІРэЃЌБШШчзжЗћДЎЕФНиШЁКѓдйЦЅХфЕШЕШЁЃ
етИіЪБКђЮвУЧЭЈГЃЛсдкSQL ServerжааДвЛИіКЏЪ§ЃЌетИіКЏЪ§НгЪеСНИіВЮЪ§ЃКColumn1ЁЂColumn2ЃЌКЏЪ§ЬхРяУцзівЛаЉТпМДІРэЃЌдкЭЈЙ§ДІРэКУЕФВЮЪ§ШЅВщбЏTable_Name2БэЃЌВЂЗЕЛиЯргІЕФжЕЁЃКмКУЃЌФЧЯТУцЮвУЧРДМЦЫуЯТЭМжаЪ§ОнЕФВщбЏЧщПіЁЃМйЩшБэ1ЕФЪ§Онга50WЃЌБэ2ЕФЪ§Онга4WЃЌдкБэ2УЛгаЫїв§ЕФЬѕМўЯТЃЌВщбЏЕФИДдгЖШОЭга50W*4WСЫЃЌСНИіБэЖМашвЊзіШЋБэЩЈУшЃЌБэ2ЕФШЋБэЩЈУшОЭЛсДяЕН50WДЮЁЃ
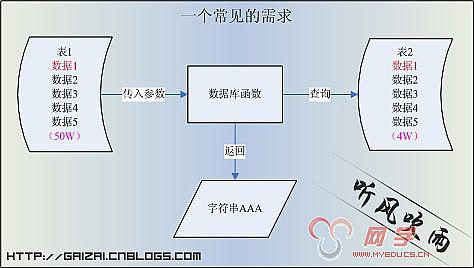
ЃЈЭМ1ЃКашЧѓЫЕУїЃЉ
гХЛЏ1ЃКетвЛИігХЛЏЃЌУПИіПЊЗЂШЫдБЖМжЊЕРЃЌФЧОЭЪЧЖдБэ2ЕФСНИіВщбЏзжЖЮЗжБ№НЈСЂЫїв§ЁЃетбљЕФгХЛЏКЭжЎЧАЯрБШЃЌадФмНЋЛсЬсИпNИіЕШМЖЁЃ
гХЛЏ2ЃКетЕкЖўИігХЛЏЗНЗЈЪЧЪЙгУSQL ServerЕФИДКЯЫїв§ЃЌдкБэ2ЩЯДДНЈвЛИіИДКЯЫїв§ЃЌетИіЗћКЯЫїв§АќРЈашвЊВщбЏЕФСНИізжЖЮЃЌЦфЪЕОЭЪЧАбСНИізжЖЮЕФФкШнЩњГЩвЛИіЫїв§ЃЌЦфжаЫїв§АќКЌСЫСНИіЫїв§ЕФХХађЁЃ
гХЛЏ3ЃКетЕкШ§ИігХЛЏЗНЗЈЪЧЪЙгУSQL Server2005жЎКѓАцБОВХгаЕФЫїв§-АќКЌадЫїв§ЃЈIncludeЃЉЃЌОЭЪЧдкгХЛЏ2ЕФЛљДЁЩЯЃЌАбашвЊЗЕЛиЕФзжЖЮвВвЛЦ№ЗХШыЕНЫїв§жаЃЌетбљЕФВщбЏОЭжЛашвЊВщбЏЫїв§ОЭЙЛСЫЃЌВЛашвЊдйЖСШЁЪ§ОнвГСЫЃЌМѕЩйДХХЬЕФIOЯћКФЁЃВЛЙ§етИіЗНЗЈвВВЛЪЧЭђФмЃЌвђЮЊгаЪБПЩФмЗЕЛиЕФзжЖЮЛсБШНЯЖрЃЌгаЪБМИИізжЖЮМгЦ№РДЕФГЄЖШгаПЩФмГЌГіСЫ900ИізжЗћЃЈЫїв§ДѓаЁЗЖЮЇЃЉЁЃ
гХЛЏ4ЃКдкВЛПМТЧвЛаЉЗжЧјЁЂЗжБэЁЂЗжЕНВЛЭЌЕФДХХЬЕШгХЛЏЗНЪНЕФЧщПіЯТЃЌЮвУЧЪЧЗёЛЙФмНјвЛВНгХЛЏЮвУЧЕФВщбЏФиЃПетОЭЪЧетЦЊЮФеТЯывЊИцЫпФуЕФЃЌвђЮЊЮвУЧЕФЛиД№ЪЧЃКгаЕФЁЃФЧОЭЪЧЭЈЙ§SQLCLRЕФUDTЃЌАбБэ2ЕФЪ§ОнвЛДЮадМгдиЕНФкДцЃЌФЧУДдкНјааБэ1ВщбЏЕФЪБКђЃЌЮвУЧВЛашвЊЭЈЙ§B+ЪїРДВщбЏЪ§ОнСЫЃЌжБНгЕНФкДцжаВщбЏЃЌетбљжЎЫљвдПьЪЧвђЮЊВйзїФкДцвЊБШВйзїДХХЬвЊПьЕУЖрЁЃетЦфжаЛсгааЉОжЯоадКЭШБЕуЃЌОпЬхМћЯТУцЕФШБЕуУшЪіЁЃ
ЩшМЦЫМТЗ
ВтЪдНсЙћ
ВтЪдЪ§ОнЃКБэ2га4.6732ЭђЬѕМЧТМЃЌБэ1га54.2524ЭђЬѕМЧТМЁЃ
ОЙ§ВтЪдЃК
ДњТы
- using System;
- using System.Data;
- using System.Data.SqlClient;
- using System.Data.SqlTypes;
- using Microsoft.SqlServer.Server;
- using System.Collections;
- using System.Collections.Generic;
- public partial class UserDefinedFunctions
- {
- //ОЙ§ВтЪдЗЂЯжЃКЪЙгУHashtableКЭSortedListУЛгаЪЙгУIDictionaryЕФадФмКУ.
- //IDictionary<string, string>жаЪЙгУstringБШSqlStringЕФадФмвЊИп.
- private static readonly IDictionary<string, string> resultCollectionDic = new Dictionary<string, string>();
- static UserDefinedFunctions()
- {
- GetTableFromDB(resultCollectionDic);
- }
- /// <summary>
- /// ДгЪ§ОнПтжаЛёШЁФГИіБэЕФЪ§Он.
- /// </summary>
- /// <param name="resultCollection"></param>
- private static void GetTableFromDB(IDictionary<string, string> resultCollectionDic)
- {
- using (SqlConnection connection = new SqlConnection("context connection=true"))
- {
- connection.Open();
- using (SqlCommand selectMGT = new SqlCommand("SELECT NS,NP,HLR FROM dbo.zh_mgt ORDER BY NS,NP", connection))
- {
- using (SqlDataReader zhmgtReader = selectMGT.ExecuteReader())
- {
- while (zhmgtReader.Read())
- {
- string NS = zhmgtReader["NS"].ToString();
- string NP = zhmgtReader["NP"].ToString();
- string HLR = zhmgtReader["HLR"].ToString();
- string key = NS + "+" + NP;
- if (!resultCollectionDic.ContainsKey(key))
- {
- resultCollectionDic.Add(key, HLR);
- }
- }
- }
- }
- connection.Close();
- }
- }
- /// <summary>
- /// БЉТЖИјSQL ServerЕїгУЕФКЏЪ§.
- /// </summary>
- /// <param name="NS">ВЮЪ§1</param>
- /// <param name="NP">ВЮЪ§2</param>
- /// <returns></returns>
- [SqlFunction(DataAccess = DataAccessKind.Read)]
- public static SqlString FunctionImsi2HLR2(string NS, int NP)
- {
- string result = null;//етРяЩшжУЮЊnullЪЧЮЊСЫдкЗНЗЈIMSI2HLR2жаХаЖЯМЬајбЛЗ.
- string key = NS + "+" + NP.ToString();//ЪЙгУЬиЪтЗћКХ+СЌНгСНИіСазїЮЊkeyжЕ.
- if (resultCollectionDic.ContainsKey(key))
- result = resultCollectionDic[key].ToString();
- return new SqlString(result);
- }
- };
ЕїгУЗНЪНЖдБШ
- --1ЃКетИіЪЧдкNPКЭNSзжЖЮжаЗжБ№НЈСЂЫїв§
- SELECT @rc=HLR FROM zh_mgt WHERE NP=7 and NS=@mgt
- --2ЃКетИіЪЧдкNPЁЂNSЁЂHLRзжЖЮжаНЈСЂСЫвЛИіАќКЌадЫїв§(Include)
- SELECT @rc=HLR FROM zh_mgt WHERE NS=@mgt and NP=7
- --3ЃКетЪЧЪЙгУSQLCLRРЉеЙКЏЪ§ЕФЕїгУЗНЗЈ
- SELECT @rc= dbo.FunctionImsi2HLR2(@mgt,7)
гХЕу
адФмЩЯЕФБШНЯЃЈетРяЕФ>ЪЧБэЪОЪБМфЕФГЄЖЬЃЌЪБМфдНаЁЃЌадФмдНгХЃЉЃКУПИіСагаЕЅЖРЕФЫїв§>ЪЙгУIncludeЕФАќКЌЫїв§>РЉеЙКЏЪ§
АбБэРяУцЕФМЧТМЗХЕНФкДцЩЯЃЌжБНгШЅФкДцЩЯВщбЏЃЌВЛашвЊЪЙгУЕНB+ЪїРДВщбЏЪ§ОнЁЃЕБФуЕФФкДцзуЙЛДѓЛђепПеЯаЃЌВЂЧвЪЙгУЕНетИіБэЕФДЮЪ§КмЖрЃЌЖјЧвИќаТВЛЦЕЗБЃЌФЧОЭПЩвдПМТЧетбљЕФгХЛЏЗНАИЁЃ
ШчЙћашвЊУцЖдвЛаЉБШНЯИДдгЕФТпМДІРэЃЌвВаэSQLЪЧУЛгаАьЗЈзіЕНЃЌМДЪЙзіЕНСЫЃЌФЧУДSQLДњТыЕФдФЖСКЭЮЌЛЄЛсБШНЯРЇФбЃЌЦфЪЕетИіМШЪЧгХЕугжЪЧШБЕуЃЌЯТУцЕФШБЕужагаЬсЕНЁЃ
ЗтзАДњТыЃЌМгЧПДњТыАВШЋЁЃ
ШБЕу
гавЛЖЈЕФОжЯоадЃЌЕБгаЖрИіANDЬѕМўвЛЦ№ВщбЏЛђепМИИіМќЭЈЙ§ЩЯУцЕФЗНЗЈМгЦ№РДЕФзжЗћДЎВЛЮЈвЛЃЌФЧУДОЭУЛгаАьЗЈЯёЩЯУцIDictionary<string, string>ЕФЗНЗЈРДЪЙгУkeyСЫЃЌЕЋЪЧвВВЛЪЧУЛгаАьЗЈЕФЃЌЦфЪЕАьЗЈОЭЪЧIListЃЌАбЮЈвЛЕФжЕзїЮЊkeyЃЌдйЙЙдьвЛИіЪЕЬхзїЮЊkeyЕФvalueЁЃ
ШчЙћБэИќаТСЫЃЌашвЊжиаТзЂВсКЏЪ§ЃЌвђЮЊГЬађвбОАбећИіБэМгдиЕНФкДцСЫЃЛШчЙћВЛжиаТзЂВсКЏЪ§ЃЌФЧУДОЭашвЊЪ§ОнПтжиЦєЗўЮёСЫЃЌвђЮЊФЧИіГЬађМЏЪЧдкЗўЮёЦєЖЏЕФЪБКђОЭГѕЪМЛЏСЫЁЃ
еыЖдЩЯУцЕкЖўИіШБЕуЃЌвВЪЧгаАьЗЈНтОіЕФЃЌФЧОЭЪЧдкБэжазівЛИіДЅЗЂЦїЃЌЕБгаInsertЁЂUpdateЁЂDeleteЕШВйзїОЭЕїгУвЛИіжиаТзЂВсЕФДцДЂЙ§ГЬОЭПЩвдСЫЁЃ
ШчЙћРяУцЕФТпМДІРэБШНЯИДдгЃЌФЧУДИќаТТпМЫљДјРДЕФВПЪ№ЁЂЮЌЛЄГЩБОБШНЯДѓЃЌвђЮЊШчЙћЪЧаДГЩКЏЪ§ЛђепЪЧНЈСЂАќКЌадЫїв§ПЩФмЛсИќКУЮЌЛЄЁЃ
вЩЮЪ
дкSQL ServerжаЃЌЖдвЛИіАќКЌадЫїв§ЕФвЩЮЪЃКБШШчгавЛИіintРраЭЕФзжЖЮКЭвЛИіnvarcharЕФзжЖЮЃЌintзжЖЮЕФжиИДТЪБШНЯДѓЃЌЖјnvarcharЕФжиИДТЪБШНЯЩйЃЌЮвжЎЧАЪЧИљОнжиИДТЪРДШЗШЯЫЗХЧАУцЕФЃЌЕЋЪЧintгыnvarcharЕФЦЅХфаЇТЪЪЧВЛвЛбљЕФЃЌintжЛвЊЦЅХфвЛДЮЃЌЖјnvarcharашвЊЦЅХфИњзжЗћДЎГЄЖШвЛбљЖрЕФДЮЪ§ЃЌФЧУДгІИУШчКЮАбЫЗХЕНЧАУцФиЃП
Ъ§ОнПтжаПЩвдАб90%ЕФВщбЏЖМЙщНсЮЊ1ЃКЭъШЋЦЅХфЃЌ2ЃКЧАзКЦЅХфЁЃЖдгІНтОіЗНАИЪЧЃК1ЃКПЩВЩгУbloom-filterРЉеЙКЏЪ§НјааИпЫйЦЅХфЃЌ2ЃКПЩВЩгУИФНјЕФЙўЗђТќЪїЁЃШчКЮзіетЗНУцЕФЗНАИФиЃП
змНс
ЫфШЛетбљЕФЗНЪНБШНЯФбдкЯжЪЕЕФдЫгУжаБЛЪЙгУЃЌвђЮЊгаКмЖрОжЯоадКЭШБЕуЃЌЕЋЪЧЮваДетЦЊЮФеТЕФГѕждОЭЪЧЯыШУДѓМвжЊЕРдкЬиЪтЕФЧщПіЯТЃЌЛЙгаетбљвЛжжгХЛЏЕФЗНЗЈПЩвдЪЙгУЁЃ
