鉴于大家对正则表达式十分关注,我们编辑小组在此为大家搜集整理了“正则表达式学习参考 正则入门学习资料”一文,供大家参考学习
1 概述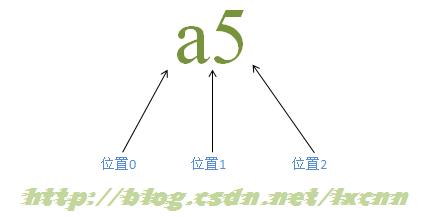
对于字符串“a5”,是由两个字符“a”、“5”以及三个位置组成的,这一点对于正则表达式的匹配原理理解很重要。
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。
占有字符还是零宽度,是针对匹配的内容是否保存到最终的匹配结果中而言的。
占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
正则表达式由两种字符构成。一种是在正则表达式中具体特殊意义的“元字符”,另一种是普通的“文本字符”。
元字符可以是一个字符,如“^”,也可以是一个字符序列,如“\w”。
字符组可以匹配[ ]中包含的任意一个字符。虽然可以是任意一个,但只能是一个。
字符组支持由连字符“-”来表示一个范围。当“-”前后构成范围时,要求前面字符的码位小于后面字符的码位。
[^…] 排除型字符组。排除型字符组表示任意一个未列出的字符,同样只能是一个。排除型字符组同样支持由连字符“-”来表示一个范围。
表达式 | 说明 |
[abc] | 表示“a”或“b”或“c” |
[0-9] | 表示0~9中任意一个数字,等价于[0123456789] |
[\u4e00-\u9fa5] | 表示任意一个汉字 |
[^a1<] | 表示除“a”、“1”、“<”外的其它任意一个字符 |
[^a-z] | 表示除小写字母外的任意一个字符 |
举例:
“[0-9][0-9]”在匹配“Windows 2003”时,匹配成功,匹配的结果为“20”。
“[^inW]”在匹配“Windows 2003”时,匹配成功,匹配的结果为“d”。
对于一些常用的字符范围,如数字等,由于非常常用,即使使用[0-9]这样的字符组仍显得麻烦,所以定义了一些元字符,来表示常见的字符范围。
表达式 | 说明 |
\d | 任意一个数字,相当于[0-9],即0~9 中的任意一个 |
\w | 任意一个字母或数字或下划线,相当于[a-zA-Z0-9_] |
\s | 任意空白字符,相当于[ \r\n\f\t\v] |
\D | 任意一个非数字字符,\d取反,相当于[^0-9] |
\W | \w取反,相当于[^a-zA-Z0-9_] |
\S | 任意非空白字符,\s取反,相当于[^ \r\n\f\t\v] |
举例:
“\w\s\d”在匹配“Windows 2003”时,匹配成功,匹配的结果为“s 2”。
小数点可以匹配除“\n”以外的任意一个字符。如果要匹配包括“\n”在内的所有字符,一般用[\s\S],或者是用“.”加(?s)匹配模式来实现。
表达式 | 说明 |
. | 匹配除了换行符 \n 以外的任意一个字符 |
表达式 | 说明 |
^ | 匹配字符串开始的位置,不匹配任何字符 |
$ | 匹配字符串结束的位置,不匹配任何字符 |
\b | 匹配单词边界,不匹配任何字符 |
举例:
“^a”在匹配“cba”时,匹配失败,因为表达式要求开始位置后面是字符“a”,而“cba”显然是不满足的。
“\d$”在匹配“123”时,匹配成功,匹配结果为“3”,这个表达式要求匹配结尾处的数字,如果结尾处不是数字,如“123abc”,则是匹配失败的。
一些不可见字符,或是在正则中具有特殊意义的元字符,如想匹配字符本身,需要用“\”对其进行转义。
